Datei-I/O-API
Grundlagen der Datei-Ein-/Ausgabe
Eine Datei ist eine vom Betriebssystem (OS) verwaltete Ressource, die im Dateisystem gespeichert und dort durch einen Dateipfad identifiziert wird. Ein Programm, das mit einer Datei arbeiten soll, muss folgende verbindliche Phasen einhalten:
- Öffnen der Datei für den beabsichtigten Zugriffstyp (Lesen / Schreiben);
- Zugriff auf den Inhalt entsprechend dem angeforderten Zugriffstyp;
- Schließen der Datei, sobald der Zugriff abgeschlossen ist.
Genauer gesagt ist keineswegs sicher, dass der Öffnungsversuch gelingt, sodass ein Fehlschlag stets berücksichtigt werden muss. Daher lohnt es sich, folgendes abstrakte algorithmisches Schema für den Umgang mit Dateien in einem Programm im Gedächtnis zu behalten:
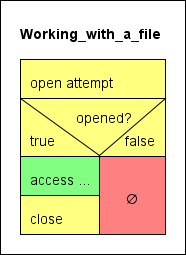
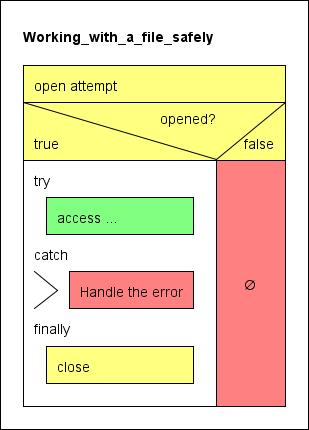
Die gelben Elemente sind die Hilfsanweisungen und -tests für die Ressourcenbeschaffung und -freigabe, das grüne Element symbolisiert die eigentliche Dateiverarbeitung, das rote Element stellt den Fehlerpfad dar. Eine etwas sicherere Variante besteht darin, TRY-Blöcke zu verwenden (eingeführt mit Version 3.29-07), um sicherzustellen, dass eine geöffnete Datei auf jeden Fall geschlossen wird, unabhängig davon, was während des Zugriffs passiert:
Die Tabelle der Dateiroutinen, die mit Release 3.26 verfügbar gemacht wurden, finden Sie auf der Seite Syntax.
Öffnen einer Datei
Ein Programm oder eine Routine muss zunächst eine Datei vom OS für einen bestimmten Zweck (Lesen oder Schreiben) anfordern, bevor es damit arbeiten kann. Structorizer bietet drei verschiedene Öffnungsfunktionen – eine für den Lesezugriff (fileOpen) und zwei für den Schreibzugriff (fileCreate und fileAppend):
fileOpenfordert eine durch einen Pfadstring (z. B."documents/nice_to_have.txt") identifizierte Datei zum Lesen von Daten an (d. h. als Eingabedatei) und setzt voraus, dass die Datei existiert und mit den Berechtigungen des Benutzers lesbar ist.fileCreatefordert eine Datei mit dem angegebenen Pfad zum Schreiben von Daten an (d. h. als Ausgabedatei). Im Gegensatz zufileOpenmuss die Datei nicht vorher existieren, aber das Verzeichnis muss dem Benutzer Schreibrechte gewähren. Wenn eine Datei mit diesem Pfad bereits existierte, wird sie ohne vorherige Warnung geleert.fileAppendfordert eine Datei (kann vorhanden sein oder nicht) zum Anhängen von Text an ihr Ende an (d. h. als Ausgabedatei), was natürlich Schreibrechte erfordert.
Jede der drei Öffnungsroutinen gibt einen ganzzahligen Wert zurück, der im Erfolgsfall als programminterner Bezeichner und Datei-Handle für alle mit der geöffneten Datei durchzuführenden Zugriffsoperationen dient. Zahlen größer als null sind gültige Datei-Handles, Zahlen kleiner oder gleich null signalisieren, dass der Öffnungsversuch fehlgeschlagen ist:
0,-1: Unspezifischer I/O-Fehler-2: Datei nicht gefunden (beifileOpen)-3: Unzureichende Berechtigungen
Sie sollten immer prüfen, ob Sie einen gültigen Handle von der verwendeten Öffnungsfunktion erhalten haben! Wenn Sie eine positive Zahl (d. h. einen gültigen Datei-Handle) erhalten haben, können Sie die entsprechenden dateibezogenen Funktionen oder Prozeduren verwenden und dabei stets den Datei-Handle als erstes Argument übergeben. Jede dieser Unterroutinen ist unzulässig, wenn der Datei-Handle 0 oder negativ ist, nicht von einer Öffnungsfunktion stammt, der Zugriffstyp nicht übereinstimmt oder die zugehörige Datei zwischenzeitlich bereits geschlossen wurde.
Schließen einer Datei
Sobald Sie nicht mehr auf eine Datei schreiben oder lesen müssen, sollten Sie die Datei mit der Prozedur fileClose (mit dem Datei-Handle als Argument) schließen. Dadurch wird die Datei als Ressource freigegeben – und bei einer zum Schreiben geöffneten Datei wird der zugehörige Puffer geleert, die Dateikonsistenz im Dateisystem sichergestellt und die Datei damit für andere Prozesse und Anwendungen zugänglich gemacht. Erst nach dem Schließen der Datei kann man sicher sein, dass die Daten dauerhaft im Dateisystem gespeichert sind.
Sobald eine Datei geschlossen ist, ist der Handle-Wert ungültig und kann nicht wiederverwendet werden. Auch wenn Sie eine Datei, die Sie zuvor verwendet haben, erneut öffnen, erhalten Sie einen neuen, anderen Handle. Die Prozedur fileClose darf nicht ein zweites Mal auf eine bereits geschlossene Datei angewendet werden.
Lesen aus einer Datei
Das Lesen ist nur möglich, wenn die Datei zuvor mit fileOpen geöffnet wurde; als Routinenargument muss der von fileOpen erhaltene Datei-Handle verwendet werden. Folgende Lesefunktionen stehen zur Verfügung:
fileReadChargibt das nächste Zeichen der Datei zurück (einschließlich Leerzeichen oder Zeilenumbruchzeichen).fileReadIntgibt einen ganzzahligen Wert zurück, wenn und nur wenn das nächste Token in der Datei ein ganzzahliges Literal ist, andernfalls wird ein Fehler ausgelöst.fileReadDoublegibt eine Gleitkommazahl zurück, wenn und nur wenn das nächste Token in der Datei ein Zahlenliteral ist (ob ganzzahlig oder nicht), andernfalls wird ein Fehler ausgelöst.fileReadkann zurückgeben:- eine ganze Zahl, wenn an der aktuellen Leseposition ein ganzzahliges Literal (z. B.
-17) folgt; - eine Gleitkommazahl, wenn ein Gleitkommaliteral (z. B.
3.6e17) folgt; - ein Array einfacher Elemente, wenn eine durch Komma getrennte Folge primitiver Typenliterale in geschweiften Klammern (z. B.
{0, 25, foo, "text without commas", 6.9}) folgt; - einen String bestehend aus dem Inhalt einer zitierten Zeichenfolge (z. B.
"This text, however, might contain commas, but no escaped quote"); - in jedem anderen Fall einen String, der die nächste nicht durch ein Leerzeichen unterbrochene Zeichenfolge umfasst (z. B.
foo).
- eine ganze Zahl, wenn an der aktuellen Leseposition ein ganzzahliges Literal (z. B.
fileReadLinegibt immer einen String zurück, der den (Rest der) aktuellen Zeile bis zum, aber nicht einschließlich des nächsten Zeilenumbruchzeichens umfasst. Das Zeilenumbruchzeichen wird jedoch verbraucht.
Da das Lesen über das Dateiende hinaus einen Fehler auslöst, empfiehlt es sich generell, die „End of File"-Eigenschaft der gelesenen Datei zu prüfen. Dies geschieht mit der Funktion fileEOF, die true zurückgibt, wenn das Dateiende erreicht ist, und false andernfalls.
Schreiben in eine Datei
Das Schreiben ist nur möglich, wenn ein gültiger (d. h. positiver) Datei-Handle von einer der Öffnungsfunktionen fileCreate oder fileAppend erhalten wurde.
fileWriteschreibt einen beliebigen Wert genau so – ohne zusätzliche Trennzeichen, Zeilenvorschübe usw. Dies ermöglicht das Zusammenstellen beliebiger Texte ohne Structorizer-Eingriffe.fileWriteLinemacht dasselbe, fügt aber ein Zeilenumbruchzeichen hinzu.
Beispiele
Die folgenden Beispiele veranschaulichen den korrekten Umgang mit Dateien:
1. FileWriteDemo
FileWriteDemo schreibt Text und über eine Eingabeanweisung erhaltene Werte in eine Datei, wobei alle Werte durch ein Leerzeichen (das „natürliche" Trennzeichen beim Lesen von Tokens aus einer Datei) getrennt werden, bis der Benutzer ein einzelnes „$"-Zeichen eingibt. Dies ergibt eine lange Textzeile in der Datei. Der Fehlerpfad ist leer, Sie könnten jedoch eine Ausgabeanweisung mit einer Fehlermeldung einfügen (siehe Beispiel 6 unten).
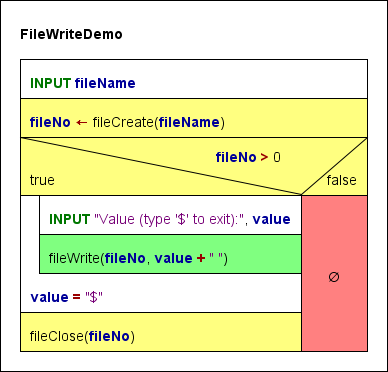
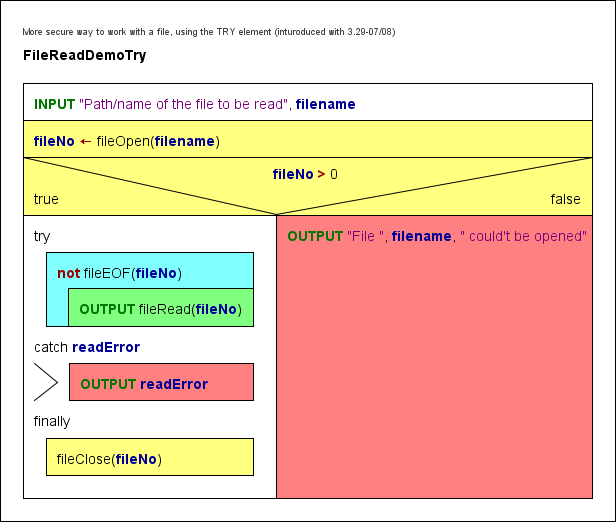
2. FileReadDemo, FileReadDemoTry
FileReadDemo geht den umgekehrten Weg: Es öffnet eine Textdatei und liest Tokens (durch Leerzeichen getrennte Teilstrings) daraus – einen pro Schleifendurchlauf –, versucht, sie als Zahlen oder standardmäßig als Strings zu interpretieren, und schreibt die interpretierten Werte nacheinander in die Ausgabe. Beachten Sie, dass die gelesenen Werte bezüglich Anzahl und Typ möglicherweise nicht mit den in die Datei geschriebenen Ausdrücken übereinstimmen. Z. B. wird ein geschriebener, nicht in Anführungszeichen gesetzter String mit Leerzeichen beim Lesen in die einzelnen „Wörter" aufgeteilt; jedes dieser „Wörter" (Tokens) wird unabhängig auf Literal-Syntax geprüft, sodass ein geschriebener String These are 4 words als vier Werte gelesen wird, drei davon (1., 2. und 4.) als Strings, einer (der 3.) als ganzzahliger Wert.
Wenn die Datei durch Anführungszeichen eingeschlossene Strings enthält (d. h. mehrere Wörter, von denen das erste mit " beginnt und das letzte (innerhalb derselben Zeile!) mit " endet), wird diese Folge als ein einziger String gelesen, wobei die Anführungszeichen entfernt werden.
Wenn die Datei durch geschweifte Klammern eingeschlossene, durch Komma getrennte Tokens enthält, z. B. {23, 7, -9.8e4, "something"}, wird zumindest versucht, diese in ein Array umzuwandeln.
In dieser Hinsicht können die eingebauten Testfunktionen isArray, isNumber, isString, isChar und isBool hilfreich sein, um die aus der Datei gelesenen Werte sinnvoll nutzen zu können.
Seit Version 3.29-08 können Sie einen noch sichereren Weg gehen, indem Sie den Dateizugriff in einem TRY-Block kapseln, um sicherzustellen, dass die Datei auf jeden Fall geschlossen wird.
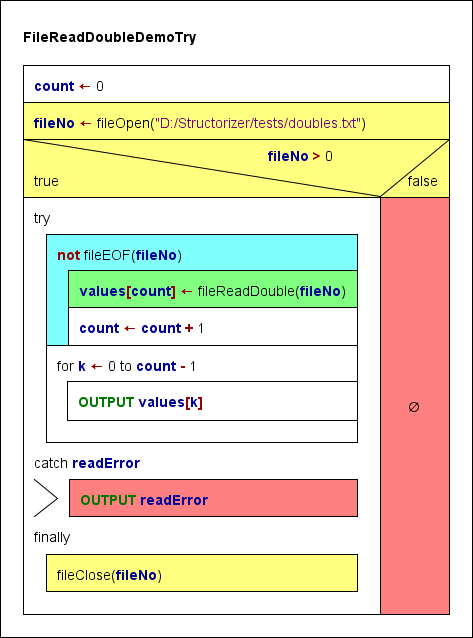
3. FileReadDoubleDemo, FileReadDoubleDemoTry
Dieser Algorithmus setzt voraus, dass die Textdatei aus mehreren durch Leerzeichen getrennten Zeichenfolgen besteht, die als Gleitkommazahlen interpretierbar sind, z. B.:4.5 -98.0e5 7
12 10293
Er liest die Werte aus der Datei als Double-Werte in ein Array und schreibt die Array-Elemente dann in die Ausgabe. Ein nicht als Zahl interpretierbares Token bricht den Algorithmus ab.

Auch dieser Algorithmus kann durch die Verwendung eines TRY-Blocks etwas sicherer gestaltet werden. Die Array-Ausgabe wurde dabei ebenfalls in den geschützten Abschnitt verlegt (auch wenn dadurch das Schließen der Datei verzögert wird), da das Array values erst innerhalb der Leseschleife eingeführt wird und daher im Fehlerfall möglicherweise nicht initialisiert ist:
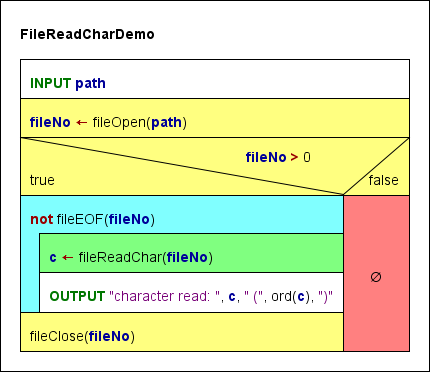
4. FileReadCharDemo
Dieser Algorithmus liest die durch den angeforderten Pfad angegebene Eingabedatei zeichenweise (einschließlich aller Leerzeichen!) und schreibt sowohl die grafische Darstellung als auch den dezimalen Code jedes Zeichens in den Ausgabestream.
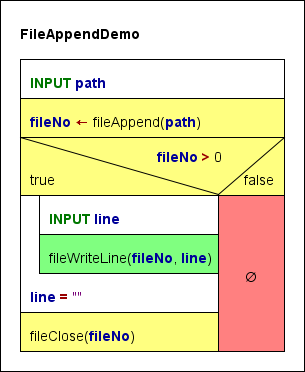
5. FileAppendDemo
Dieser Algorithmus versucht, eine Textdatei zum Schreiben zu öffnen, ohne ihren bisherigen Inhalt zu löschen, und fügt die interaktive Benutzereingabe als zusätzliche Zeilen an ihr Ende an. Der Benutzer kann die Schleife durch Lassen des Texteingabefeldes leer beenden.
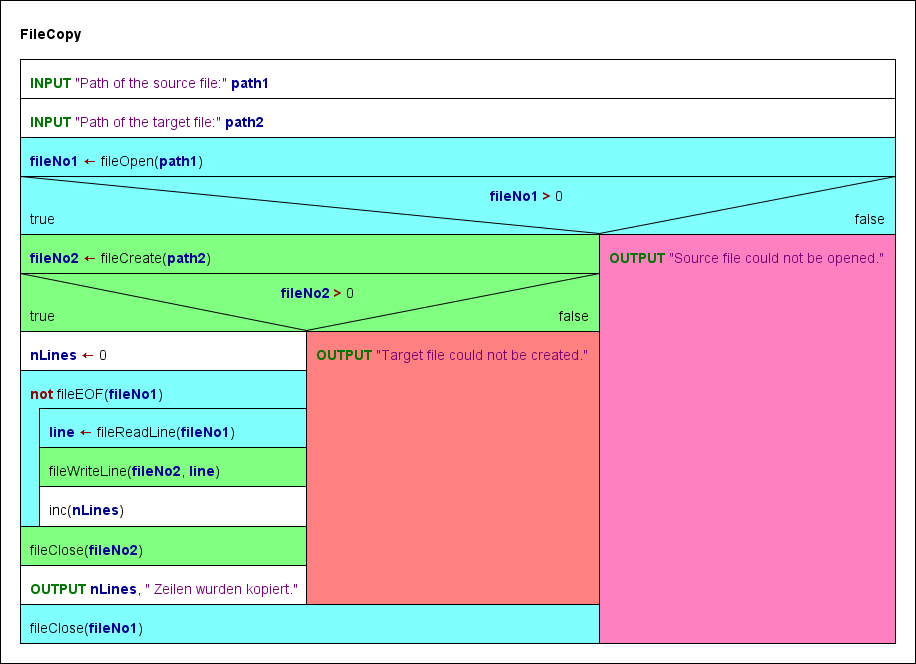
6. FileCopy
Das letzte Diagrammbeispiel demonstriert, wie man eine Textdatei zeilenweise kopiert. Die cyanfarbenen Elemente beziehen sich auf die Quelldatei, die grünen Elemente auf die Zieldatei. Die roten und rosafarbenen Elemente sind die Fehlerpfade für die Öffnungsversuche.
Code-Export
Es wurden Anstrengungen unternommen, die Code-Generatoren von Structorizer dazu zu bringen, ein mehr oder weniger sinnvolles Äquivalent von Algorithmen, die Structorizer-Datei-API-Routinen verwenden, im Zielcode zu erzeugen. Bei einigen Sprachen konnte eine relativ einfache Transformation gefunden werden; bei anderen (z. B. C++, C#, Python) muss möglicherweise eine statische Objektklasse „StructorizerFileAPI", die die Structorizer-Datei-API emuliert, in den resultierenden Code eingefügt oder diesem zugeordnet werden, wo eine direkte Substitution nicht möglich war. Der Java-Export fügt der resultierenden Klasse selbst einige private statische Methoden hinzu.
Sehr unterschiedliche Arten von Datei-Handles oder ein ausnahmebasiertes Funktionskonzept haben es äußerst schwierig oder gar unmöglich gemacht, einen einigermaßen kompatiblen Test auf Erfolg zu konstruieren oder würden eine Neugestaltung des gesamten Algorithmuskontexts erfordern.
Der Code-Export in die Shell-Skriptsprachen bash und ksh musste dem vollständig anderen Paradigma des Dateihandlings kapitulieren, bei dem man Standardeingabe oder -ausgabe in Textdateien umleiten müsste. Eine vollständige (100 %) semantische Äquivalenz ist daher nicht zu erwarten, auch nicht bei Hochsprachen, obwohl deren Dateikonzepte in etwa vergleichbar sind.
Structorizer bietet derzeit noch keine Exportlösungen für Oberon und BASIC. Ansätze könnten jedoch in späteren Versionen hinzugefügt werden.