Komplexe Datentypen
Arrays
Structorizer unterstützt die Verwendung von Arrays, grundsätzlich von eindimensionalen Arrays. Technisch gesehen bietet Structorizer keine mehrdimensionalen Arrays. Wenn Sie jedoch Arrays in die Elemente (eindimensionaler) Arrays einbetten, nähert sich das Verhalten einer Annäherung an mehrdimensionale Arrays.
Eindimensionale Arrays können auf zwei Arten eingeführt werden:
1. Elementweise Zuweisung (inkrementelles Wachstum)
Sobald Sie eine Zuweisungs- oder Eingabeanweisung schreiben und dem Zielvariablennamen eckige Klammern mit einem Indexausdruck anhängen, wird die Variable zu einer Array-Variablen gemacht (sofern sie es noch nicht ist):
names[2] <- "Goofy"
INPUT x[0]Der Indexbereich von Arrays beginnt bei 0. Wenn Sie einem Array-Element mit einem größeren Index als bisher verwendet etwas zuweisen, wird das Array automatisch bis zum neuen Index erweitert. Wenn es Indexlücken gibt, werden die dazwischenliegenden Elemente mit 0 gefüllt, z. B. würde im ersten obigen Beispiel das resultierende Array names wie folgt gefüllt sein: {0, 0, "Goofy"}. Beachten Sie, dass ein Lesezugriff mit einem Index, der größer als der höchste bisher für Zuweisungen oder Eingaben verwendete Index ist, die Ausführung mit einer Fehlermeldung abbricht.
Seit Version 3.32-25 ist es sogar möglich, einige mehrdimensionale array-ähnliche Konglomerate zu erstellen, indem anfänglich einer neuen Variablen mit mehreren Indizes ein Wert zugewiesen wird (beachten Sie jedoch, dass das Ergebnis eine ziemlich spärlich gefüllte Array-von-Arrays-Struktur ist, in der nur der angegebene Indexpfad vollständig angelegt wird):
matrix[3,2,4] <- 27.5
INPUT A[0][6]Im ersten obigen Beispiel wird die resultierende verschachtelte Array-Struktur matrix wie folgt gefüllt: {{{}}, {{}}, {{}}, {{}, {}, {0, 0, 0, 27.5}}}.
2. Listeninitialisierung
Sie können eine Array-Variable mit einer Liste von Elementwerten initialisieren, die in geschweifte Klammern eingeschlossen sind (wie in C, Java usw.):
values <- {17, 23.4, -9, 13}
friends <- {"Peter", "Paul", "Mary"}Sie können die Initialisierung mit einer Deklaration in einem von mehreren syntaktischen Stilen kombinieren (Pascal oder, seit Version 3.32-04, auch Java/C#):
var values: array of int <- {17, 23.4, -9, 13}
string[] friends <- {"Peter", "Paul", "Mary"}Version 3.24-10 hat die Möglichkeit eingeführt, einen solchen Initialisierungsausdruck auch im Textfeld eines Eingabedialogs (der durch eine ausgeführte Eingabeanweisung aufgerufen wird) bereitzustellen und damit die Eingabevariable zu einer Array-Variablen zu machen:
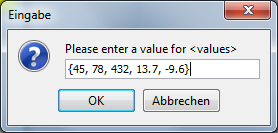
Tatsächlich ist es in Structorizer nicht notwendig (jedoch sehr empfehlenswert für die Verarbeitungsalgorithmen), dass alle Elemente eines Arrays vom gleichen Typ sind.
Arrays können als Argumente an eine Unterroutine übergeben werden (der Mechanismus ist Aufruf per Referenz, d. h. Änderungen am Array-Inhalt werden an den aufrufenden Algorithmus weitergegeben und sind für ihn sichtbar, sofern das Argument kein Initialisierungsausdruck ist und der Parameter nicht als const deklariert wurde). Routinen können auch Arrays als Ergebnis zurückgeben.
Arrays sollten nicht in die Ausdrucksliste einer Ausgabeanweisung eingebettet werden. Eine elementweise Ausgabe wird empfohlen. (Auch wenn der Executor mit der direkten Ausgabe von Arrays umgehen kann, erzeugt der Code-Export in diesem Fall normalerweise keinen sinnvollen Code.) Wenn eine auf oberster Ebene ausgeführte Unterroutine jedoch ein Array zurückgibt, wird der Array-Inhalt in einer scrollbaren Listenansicht präsentiert. Dies ermöglicht das separate Testen von Unterroutinen, bei denen einige Parameter ein Array sein müssen (bei der Ausführung auf oberster Ebene werden Parameterwerte interaktiv abgefragt, und die Eingabe einer Werteliste in geschweiften Klammern liefert ein Array, siehe oben) oder die ein Array zurückgeben. Gleiches gilt übrigens für Record-Variablen oder -Ausdrücke.
Array-Variablen oder in Klammern gesetzte Wertelisten (sogenannte Array-Initialisierungsausdrücke) sind die natürlichen Dinge, die als Kollektionen in FOR-Schleifen der Art TRAVERSIERUNG (FOR-IN-Schleifen) verwendet werden. Weitere Einzelheiten finden Sie auf der FOR-Schleifen-Benutzerhandbuchseite.
Das folgende NSD zeigt einige fortgeschrittene Beispiele für ausführbare und exportierbare Array-Operationen:

Wie bereits oben erwähnt, können Sie ganze Arrays als Elemente in andere Arrays einbetten (siehe fünfte Anweisung im Beispieldiagramm oben, wo eines der Elemente für mixedArray das zuvor gefüllte Array namens numbers ist; die zweite Anweisung zeigt jedoch keine verschachtelten Arrays, sondern die Verwendung eines Index, der aus demselben Array entnommen wurde, was etwas bizarr anmutet, aber manchmal zur Indirektion verwendet wird). Daher ist es möglich, etwas zu konstruieren, das einem mehrdimensionalen Array ähnelt (obwohl es keines ist). Die letzte Anweisung oben zeigt den kaskadierenden Indexzugriff zum Schreiben eines Elements eines inneren Arrays. Ab Version 3.32-11 können Sie sogar eine Indexliste in eckigen Klammern schreiben, um die verketteten Klammern abzukürzen, sodass a[i,j] äquivalent zu a[i][j] ist.
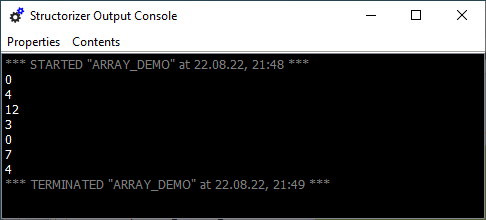
Beachten Sie jedoch, dass Structorizer keine orthogonalen mehrdimensionalen Arrays garantiert, bei denen alle Zeilen die gleiche Anzahl von Spalten haben usw. Die „Zeilen" können stattdessen unterschiedliche Inhaltsformen haben. Es liegt also vollständig in Ihrer Verantwortung sicherzustellen, dass ein kombinierter Indexzugriff sinnvoll und strukturell interpretierbar und korrekt ist.
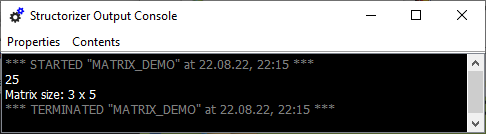
Um ein Ersatz für ein kleines mehrdimensionales Array zu konstruieren, können Sie einen verschachtelten Array-Initialisierungsausdruck verwenden, z. B.:

Dann können Sie auf jedes der Elemente zugreifen und die Länge (Elementanzahl) eines Arrays abfragen, unabhängig davon, ob es verschachtelt ist:
In keinem Fall können Sie jedoch ein äußeres Array eines „mehrdimensionalen" Konglomerats inkrementell erweitern, indem Sie versuchen, einem (nicht existierenden) Element eines fiktiven Arrays an einem höheren Index als dem bereits vorhandenen einen Wert zuzuweisen:

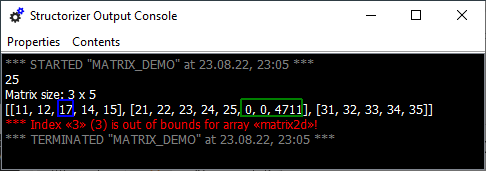
Die letzte Anweisung versucht, den Wert -9 dem Element 0 eines Arrays zuzuweisen, das sich im nicht existierenden Zeile-3-Element des äußeren Arrays befinden soll. Das automatische Erweitern des äußeren Arrays würde hier nicht einmal helfen, da dadurch nicht das erforderliche innere Array erstellt wird. In diesem Fall müsste eine zweiteilige Sequenz durchgeführt werden:
- Ein neues Teilarray an matrix2d anhängen, z. B.:
matrix2d[3] ← {41, 42, 43, 44, 45} - Das Element an der interessanten (und nun existierenden) Stelle überschreiben:
matrix2d[3][0] ← -9
Strings
Strings werden in Structorizer nicht als Arrays behandelt. (Stattdessen verhalten sie sich wie Objekte der Java-Klasse java.lang.String, weil sie das tatsächlich sind.) Das bedeutet: Sie können die Länge eines Strings s entweder ermitteln, indem Sie die Java-Methode length() darauf anwenden — s.length() — oder indem Sie die eingebaute Funktion length(s) verwenden. Der Zeichenzugriff über Indexklammern wird nicht unterstützt. Um auf ein Zeichen in einem String s zuzugreifen, können Sie entweder s.charAt(i) schreiben, wobei i von 0 bis s.length()-1 zählt, oder Sie verwenden die eingebaute Funktion copy(s, i, 1), die tatsächlich einen Teilstring der Länge 1 extrahiert (was jedoch nicht dasselbe wie ein Zeichen ist) an Position i, wobei i von 1 bis s.length() reicht; Sie können auch eine FOR-IN-Schleife über eine String-Variable iterieren lassen (wobei die Schleifenvariable tatsächliche Zeichen erhält):

Sie können kein Zeichen innerhalb des Strings ersetzen. Sie können nur neue Strings bilden, indem Sie die eingebauten String-Funktionen (siehe obige Referenz) verwenden oder Strings mit dem Operator + verketten.
Records / Structs
Seit Release 3.27 unterstützt Structorizer auch die Verwendung von Records (auch bekannt als Structs). Wie Arrays sind Records komplexe Datenstrukturen, die die Möglichkeit bieten, verschiedene Daten innerhalb einer Variablen zu kombinieren. Im Gegensatz zu Arrays haben Records benannte Komponenten, die explizit von unterschiedlichen Datentypen sein können. Denken Sie an ein Datum des Gregorianischen Kalenders, bestehend aus einem Jahr, einem Monat und einer Tagesnummer. Sie könnten ein Array aus drei Zahlen in einer festen Reihenfolge verwenden, aber es wäre ausdrucksstärker, auf die Komponenten über Namen zuzugreifen. Die Komponentennamen und -typen müssen natürlich deklariert werden, um einen eindeutigen Zugriff zu ermöglichen. Ebenso möchten Sie möglicherweise Daten über Personen kombinieren, z. B. ihren Namen, ihre Größe, ihr Geschlecht und – hey! – ihr Geburtsdatum. Sie sollten also in der Lage sein, Records auf anderen Arten von Records aufzubauen und diesen Konstrukten einen eindeutigen Namen zu geben.
Dafür wurde eine Typdefinitionssyntax eingeführt.
Typdefinitionen sind in gewöhnlichen Elementen der Art Instruction zu platzieren, obwohl eine Typdefinition nichts weiter tut, als Structorizer ab diesem Element mitzuteilen, wie Variablen dieser Art strukturiert sind. Die Typdefinition für einen Record-/Struct-Typ beschreibt die Struktur und führt einen benutzergewählten Namen für diese Konstrukte ein:
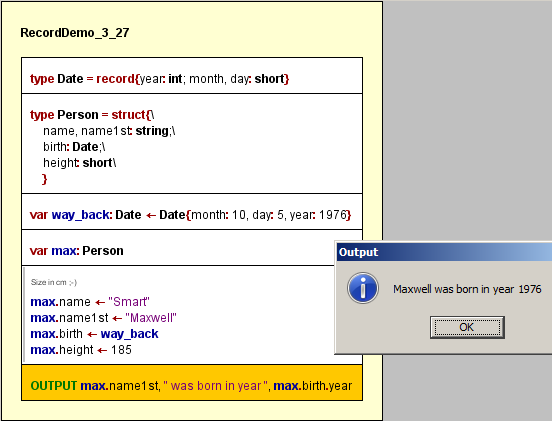
Die ersten beiden Elemente zeigen Record-Typdefinitionen. Jede beginnt mit dem Schlüsselwort type, dann ist der Name für den Typ anzugeben, gefolgt von einem Gleichheitszeichen und einem der äquivalenten Schlüsselwörter record oder struct sowie den Komponentendeklarationen in geschweiften Klammern. Jede Komponente muss einen Namen erhalten und sollte einen Typ erhalten. Das dritte Element des Diagramms zeigt eine Record-Variablendeklaration mit Initialisierung über einen „Record-Literal" (oder einen Initialisierungsausdruck). Der Initialisierer ähnelt den Typspezifikationen, beginnt aber mit dem zuvor definierten Typnamen anstelle von struct oder record. Anstelle von Komponententypnamen müssen nun den Feldnamen geeignete Werte zugeordnet werden. Die Reihenfolge der Felder ist dabei beliebig.
Das vierte Element des Diagramm-Screenshots zeigt eine bloße Deklaration (ohne Initialisierung), während in der fünften Anweisung separate Komponentenzuweisungen an die anderweitig nicht initialisierte Variable max folgen.
Ab Version 3.32-11 unterstützt der Elementeditor Sie mit Vorschlägen für Komponentennamen, wenn Sie nach einer (möglicherweise komplexen) Variablen, für die Structorizer aus den Typdefinitionen und vorangegangenen Deklarationen eine Record-Struktur ableitet, einen Punkt eingeben:
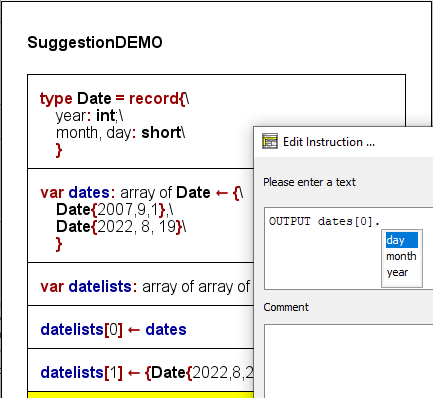
Sie können einfach einen der Komponentennamen aus der Dropdown-Liste auswählen und ihn durch Drücken der Taste Enter in den Textbereich einfügen.
Seit Version 3.28-06 werden „intelligente" Record-Initialisierer unterstützt, deren Itemliste bloße Ausdrücke enthalten kann – vorausgesetzt, ihre Reihenfolge entspricht der der Komponentendeklarationen in der zugehörigen Record-Typdefinition. So könnte Variable way_back auch wie durch die grüne Anweisung in dem modifizierten Diagramm-Ausschnitt unten gezeigt initialisiert worden sein:
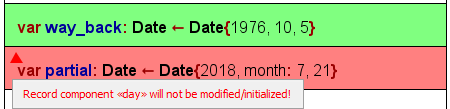
Ab dem ersten explizit vorkommenden Komponentennamen ignoriert das Parsing jedoch alle verbleibenden Werte ohne Komponentennamen-Präfix, sodass im Beispiel der roten Anweisung nur die Komponenten year und month des Records partial zugewiesen würden, während der Wert 21 ignoriert wird. (Wie der Tooltip im Screenshot zeigt, wird der Analyser warnen, dass die Komponente day nicht initialisiert wird.)
Ab Version 3.32.12 unterstützt Structorizer auch Typdefinitionen für Array-Typen sowie Alias-Typdefinitionen:
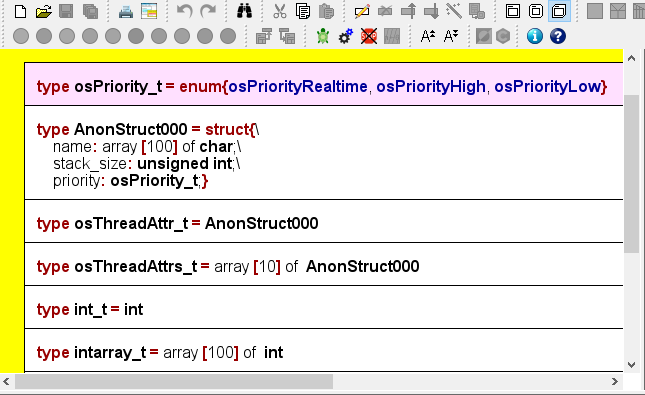
Wenn Sie Variablen eines bestimmten Record-Typs als Parameter an ein Unterroutinen-Diagramm übergeben, entsteht ein Dilemma: Wo soll die Typdefinition platziert werden, damit die Parameterstruktur in beiden Diagrammen verfügbar ist? In diesem Fall kann die Typdefinition nur in einem Includable-Diagramm platziert werden, das dann sowohl vom aufrufenden als auch vom aufgerufenen Diagramm einzubinden ist.
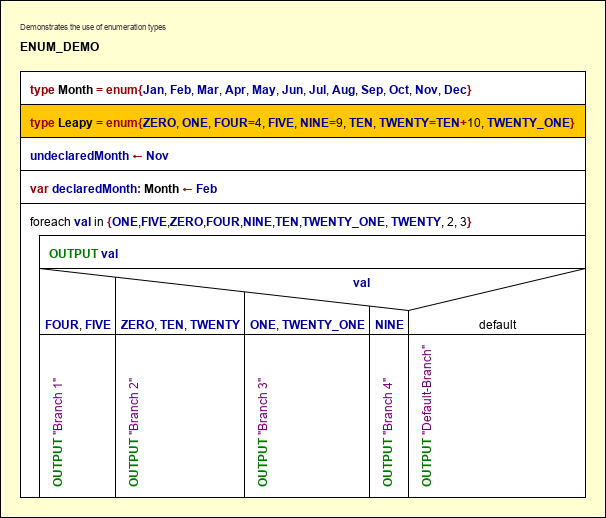
Enumeratoren (Versionen ≥ 3.30-03)
Häufig hat man es mit einem Datentyp zu tun, der einen aus einer endlichen und fixen Menge von Kategorien repräsentieren soll, z. B. den Wochentag (Montag / Dienstag / Mittwoch / Donnerstag / Freitag / Samstag / Sonntag) oder einen Universitätsmitgliedsstatus (Student / Assistent / Professor) oder ähnliches. Natürlich könnten Sie diese Werte mit ganzen Zahlen kodieren, aber es wäre lesbarer und verständlicher, wenn Sie symbolische Bezeichnungen verwenden könnten. Die Verwendung von Strings als Alternative kann eine schlechte Option sein, da sie mehr Speicher kosten und nur schlechte Möglichkeiten bieten, die Korrektheit eines solchen Werts statisch sicherzustellen und zu prüfen (z. B. gegen falsche Schreibweise). Die meisten Programmiersprachen bieten daher das Konzept sogenannter Enumerationstypen. Tatsächlich ist ein Enumerationstyp nichts weiter als eine Menge benannter ganzzahliger Konstanten, die durch Aufzählung ihrer Bezeichner eingeführt wird.
In Structorizer kann ein Enumerationstyp auf folgende Weise definiert werden:

type und enum sind reservierte Wörter; der Bezeichner zwischen type und = wird zum Namen des Enumerationstyps; die zwischen den geschweiften Klammern aufgelisteten Bezeichner sind die zu definierenden Enumeratorkonstanten. Structorizer weist den Enumeratorelementen in der aufgelisteten Reihenfolge aufeinanderfolgende ganzzahlige Codes zu, d. h. der erste Name (z. B. Monday) wird mit 0 assoziiert, der zweite mit 1 und so weiter.
Wenn die Kodierung in einem bestimmten Fall eine Rolle spielt, können Sie einigen Enumeratorbezeichnern explizit einen Codewert zuweisen, wie das orangefarbene Element im Demo-Diagramm unten zeigt. Das erforderliche Operatorsymbol ist =, der Code muss ein konstanter ganzzahliger Wert sein (idealerweise ein Literal wie 42), kann jedoch als einfacher konstanter Ausdruck, d. h. als arithmetische Berechnung aus ganzzahligen Konstanten (ganzzahligen Literalen oder zuvor definierten Konstanten, einschließlich Enumeratorbezeichner) angegeben werden, wie unten dargestellt. Nachfolgende Enumeratorelemente werden ab dem explizit zugewiesenen Element inkrementell kodiert.