Grundlegende syntaktische Konzepte
Rekursive „Definition"
Ein grundlegendes Konzept ist das des Ausdrucks. Ein Ausdruck beschreibt einen (nicht notwendigerweise numerischen) Wert oder die Operationen zur Berechnung eines Werts aus anderen Werten mittels Funktionen und Operatoren auf eine mehr oder weniger natürliche Weise. Offensichtliche Beispiele für Ausdrücke sind:
4 + 7
r * sin(x)
sqr(a + b)Im Folgenden wird eine halbformale rekursive Syntaxeinführung gegeben, in der in einigen Fällen eine Art erweiterter Backus-Naur-Form als bekanntes Beschreibungsformat verwendet wird (wenn auch hier nicht ganz exakt). Metasymbole sind:
- spitze Klammern
<,>umschließen ein nichtterminales Konzept, das durch Grammatikregeln definiert wird, - das Definitionssymbol
::=trennt das zu definierende Konzept von den ersetzenden Symbolen, - senkrechte Striche
|trennen alternative Regeln innerhalb einer kombinierten Regel, - Klammern
(,)gruppieren z. B. alternative syntaktische Teile innerhalb einer Regel, - eckige Klammern
[,]umschließen optionale Teile, - geschweifte Klammern
{,}umschließen wiederholte Teile innerhalb einer Regel.
Wo die oben genannten Zeichen nicht als Metasymbole, sondern als terminale Symbole (tatsächliche Zeichen der definierten Sprache) gemeint sind, werden sie zur Unterscheidung unterstrichen. Atomare Ausdrücke sind Literale und Bezeichner.
Literale
- Die Schlüsselwörter
trueundfalsesind boolesche Literale.
<literal_bool> ::= true | false - Eine Folge von Ziffern, optional mit einem Vorzeichen, ist ein ganzzahliges Literal:
<digit> ::= 0|1|2|3|4|5|6|7|8|9
<literal_int> ::= [+|-] <digit> {<digit>} - Eine Folge von Ziffern und Buchstaben A…F oder a…f nach dem Präfix
0xist ein hexadezimales ganzzahliges Literal:
<hex_digit> := <digit>|A|B|C|D|E|F|a|b|c|d|e|f
<literal_hex> ::= 0x<hex_digit> {<hex_digit>} - Ein ganzzahliges Literal gefolgt vom Zeichen
List ein langer ganzzahliger Literal.
<literal_long> ::= <literal_int>L - Eine Folge von Ziffern mit einem Dezimalpunkt oder einem Exponentialpostfix ist ein Gleitkomma-Literal; das Schlüsselwort
Infinityund das Symbol ∞ sind ebenfalls Gleitkomma-Literale (seit Version 3.30-15):
<literal_float> ::= <literal_int> . <digit>{<digit>} [ E [+|-] <digit>{<digit>} ]
| [+|-] . <digit> {<digit>}[ E [+|-] <digit>{<digit>} ]
| Infinity | ∞ - Ein einzelnes druckbares Zeichen (außer einem einfachen Anführungszeichen), eingeschlossen in Apostrophe (d. h. einfache Anführungszeichen), gilt als Zeichen-Literal:
<literal_char> ::= '<character>'
Bestimmte Escape-Notationen wie z. B.'\n','\t','\0','\''und'\u0123'sind ebenfalls gültige Zeichen-Literale. - Andere in einfache oder doppelte Anführungszeichen eingeschlossene Zeichenfolgen sind String-Literale (sofern es kein Zeichen-Literal ist); ein String-Literal darf auch bestimmte Escape-Sequenzen enthalten (insbesondere muss das schließende Trennzeichen, also ein einfaches bzw. doppeltes Anführungszeichen, mit einem vorangestellten Backslash maskiert werden, wenn es innerhalb des String-Literal-Inhalts vorkommt).
<literal_string> ::= " {<character>} " | ' {<character>} ' - Ganzzahl-, Long- und Gleitkomma-Literale können zusammenfassend als numerische Literale bezeichnet werden:
<literal_num> ::= <literal_int> | <literal_hex> | <literal_long> | <literal_float>
Beispiele:
trueist ein boolesches Literal, das den logischen Wert WAHR bedeutet.-12ist ein ganzzahliges Literal mit dem offensichtlichen Wert minus zwölf.12.97und-6.087e4sind nicht-ganzzahlige (Gleitkomma-)numerische Literale.'9'ist kein numerisches, sondern ein Zeichen-Literal."Achtung!"und'mehr als 1 Zeichen'sind String-Literale."Er nannte mich \"Idiot\" als ich ging."und'ist"ok'sind gültige String-Literale,"oh"nein"ist es nicht.'a'ist ein Zeichen-Literal, während"a"ein String-Literal ist.- ∞ ist ein Gleitkomma-(
double-)Literal, das einen unendlich großen positiven Wert bedeutet (entsprichtInfinity).
Bezeichner
Ein Bezeichner ist ein Name für bestimmte Konzepte. Im Gegensatz zu Literalen erfordern Bezeichner eine benutzerspezifische Deklaration oder Einführung, die sie mit einem Speicherplatz, einem Wert oder z. B. einem Typ verknüpft.
- Eine zusammenhängende Folge von ASCII-Buchstaben, Ziffern und Unterstrichen, die idealerweise mit einem Buchstaben beginnt und jedenfalls nicht mit einer Ziffer beginnt, ist ein Bezeichner:
<letter> ::= A|B|C|...|Z|a|b|c|...|z
<identifier> ::= (_|<letter>){_|<letter>|<digit>}
Beispiele:
kill_billist ein Bezeichner,off the recordist es nicht (innerhalb eines Bezeichners darf es keine Leerzeichen geben).Infinity,trueundfalsegelten nicht als Bezeichner, da sie als Literal-Schlüsselwörter reserviert sind.
Ausdrücke
- Literale (siehe oben) sind (atomare) Ausdrücke.
- Variablenbezeichner sind (atomare) Ausdrücke, die einen Speicherort angeben, der einer Variablen oder einem strukturellen Teil davon zugeordnet ist, z. B. einem Element einer Array-Variablen oder einer Komponente einer zusammengesetzten (Record-/Struct-)Variablen. Da Datenstrukturen verschachtelt sein können, kann ein Variablenbezeichner eine lange Sequenz sein, die mit einem Bezeichner (dem Variablennamen) beginnt, gefolgt von vielen Accessoren (klammereingeschlossenen Indexlisten oder durch Punkte verknüpften Komponentenselektoren). Semantisch ist ein Variablenbezeichner nur gültig, wenn die Sequenz der Accessoren der verschachtelten Struktur der Variablen entspricht, die z. B. durch eine Variablendeklaration (üblicherweise in Verbindung mit Typdefinitionen), eine Initialisierung oder eine Zuweisung festgelegt wird.
<var_desig> ::= <identifier> | <var_desig> <accessor>
<accessor> ::= . <identifier> | [ <int_expr_list> ]
<int_expr_list> ::= <int_expr> { , <int_expr> }
Ein<int_expr>ist lediglich ein<expression>, dessen Wert eine ganze Zahl sein muss.
Beispiele:person,today.month,readings[k],staff[i+5].date_of_birth.year,chess.board[row, column],matrix[i][j][k] - Ein Funktionsaufruf ist ein atomarer Ausdruck. Er besteht aus einem Bezeichner gefolgt von einem Klammerpaar, das eine (möglicherweise leere) kommagetrennte Liste von Ausdrücken einschließt. Hinweis: Obwohl Prozeduraufrufe syntaktisch gleich aussehen (siehe unten), geben Funktionen beim Aufruf einen Wert zurück, während Prozeduren dies nicht tun. Daher sind Prozeduraufrufe keine Ausdrücke, sondern Anweisungen (siehe unten).
<func_call> ::= <identifier> ( <expression_list> )
<expression_list> ::= | <expression_list> , <expression>
Beispiele:sin(alpha),copy("comparsery", 5, 4) - Durch geeignete Operatorsymbole verknüpfte Ausdrücke sind Ausdrücke. Die folgenden rekursiven Regeln spiegeln die Operatorpriorität wider:
<factor> ::= [ + | - ] <atomic_expression>
<not_expr> ::= (not | !) <atomic_expression>
<mult_expr> ::= <factor> | <mult_expr> ( * | / | div | mod | % ) <factor>
<add_expr> ::= <mult_expr> | <add_expr> ( + | - ) <mult_expr>
<log_expr> ::= <add_expr> ( = | == | <> | < | > | <= | >= ) <add_expr> | <not_expr>
<log_and_expr> ::= <not_expr> | <log_and_expr> ( and | && ) <log_expr>
<log_expression> ::= <log_and_expr> | <log_expression> ( or | || | xor ) <log_expression>
<cond_expr> ::= <log_expression> ? <expression> : <cond_expr> - Ein in Klammern eingeschlossener Ausdruck ist ein atomarer Ausdruck.
Beispiele:(23.5),(a[i]),(23 * (17 + length("some text"))) - Eine kommagetrennte Liste von Ausdrücken, eingeschlossen in geschweifte Klammern, ist ein Array-initialisierender Ausdruck (nur verwendbar in Zuweisungen, als Routinenargumente, als Eingabe und in FOR-IN-Schleifen). Die Liste darf leer sein.
<init_expr_a> ::= { <expression_list> }
Beispiele:{2, 3, 5, 7, 11, 13, 17},{},{"Fruit", "flies", "like", "banana"},{17.3*4, sqrt(2.9), pow(1.2, k), log(val)} - Ein definierter Record-Typbezeichner, gefolgt von einem Paar geschweifter Klammern, das kommagetrennte Tripel aus deklariertem Komponentenbezeichner, Doppelpunkt und Ausdruck enthält, ist ein Record-initialisierender Ausdruck.
<init_expr_r> ::= <identifier> { <comp_init_list> }
<comp_init_list> ::= | <comp_init_list> , <comp_init>
<comp_init> ::= <identifier> : <expression>
Beispiele:Date{2023, 10, 14},Employee{"Dough", "John", Date{1995, 12, 24}, HEAD_OF_DPT},UnitValue{130, KMPH}- Seit Version 3.28-06 wird ein intelligenter Record-initialisierender Ausdruck unterstützt. Er beginnt weiterhin mit einem definierten Record-Typbezeichner, aber das folgende Klammerpaar kann eine bloße Ausdrucksliste enthalten (wie beim Array-initialisierenden Ausdruck). In diesem Fall werden die Werte den Komponenten in der Reihenfolge ihrer Deklaration in der jeweiligen Record-Typdefinition zugewiesen. Es darf nicht mehr Ausdrücke in der Liste als Komponenten im Typ geben (es dürfen aber weniger sein). Es ist auch erlaubt, dass einer unvollständigen Ausdrucksliste eine Sequenz von kommagetrennnten Tripeln aus Name, Doppelpunkt und Ausdruck folgt. Einfache Ausdrücke nach einem Komponenteninitialisierungs-Tripel werden jedoch ignoriert (Beispiele siehe Records).
<comp_init> ::= [ <identifier> : ] <expression>
- Seit Version 3.28-06 wird ein intelligenter Record-initialisierender Ausdruck unterstützt. Er beginnt weiterhin mit einem definierten Record-Typbezeichner, aber das folgende Klammerpaar kann eine bloße Ausdrucksliste enthalten (wie beim Array-initialisierenden Ausdruck). In diesem Fall werden die Werte den Komponenten in der Reihenfolge ihrer Deklaration in der jeweiligen Record-Typdefinition zugewiesen. Es darf nicht mehr Ausdrücke in der Liste als Komponenten im Typ geben (es dürfen aber weniger sein). Es ist auch erlaubt, dass einer unvollständigen Ausdrucksliste eine Sequenz von kommagetrennnten Tripeln aus Name, Doppelpunkt und Ausdruck folgt. Einfache Ausdrücke nach einem Komponenteninitialisierungs-Tripel werden jedoch ignoriert (Beispiele siehe Records).
Zusammenfassung:
<atomic_expression> ::= <literal> | <var_desig> | <func_call> | ( <expression> )
<expression> ::= <add_expression> | <log_expression> | <init_expr_a> | <init_expr_r> | <cond_expr>- Es gibt keine weiteren Ausdrücke.
- Der Typ eines Ausdrucks wird aus den verwendeten Operatoren und Operandenausdrücken sowie Funktionen abgeleitet. (Die ungenauen BNF-Fragmente oben sollten nur eine vage Vorstellung davon vermitteln, wie Typableitung grammatikalisch funktionieren könnte. Eine halbwegs exakte parsbare Grammatik würde weit mehr nichtterminales Vokabular und Hunderte von BNF-Regeln mit dem Hauptschwachpunkt undeklartierter Variablen erfordern.)
- Ein boolescher Ausdruck kann mit Vergleichsoperatoren gebildet werden oder aus Operanden mit booleschem Wert bestehen usw.
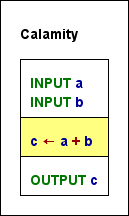
- Bei der Ausführung ist die Syntax kontextsensitiv, d. h. die tatsächlichen Variablen- und Konstantentypen entscheiden, ob der Ausdruck wohlgeformt ist und ausgewertet werden kann. Sein Ergebnistyp ist dann aber eindeutig. Betrachten Sie folgendes Diagramm. Es sieht recht einfach und geradlinig aus, oder? Gibt man 5 und 7 ein, ergibt sich 12 – gut. Aber was passiert, wenn der Benutzer einen Array- oder Record-Initialisierungsausdruck eingibt? Dann wäre der gelbe Ausdruck vollständig illegal! Ist eine der Eingaben ein String, wird Variable c zu einem String; wenn eines von a oder b gleich
falseodertrueist, ist das Ergebnis wiederum illegal; bei zwei numerischen Werten wird c eine Gleitkommazahl, wenn a oder b mit einem Dezimalpunkt eingegeben wurden, sonst möglicherweise ein ganzzahliges Ergebnis. Und so weiter.
Anweisungen
Anweisungen beschreiben eine ausführbare Aktion. In vielen traditionellen Programmiersprachen sind Anweisungen keine Art von Ausdruck, und auch in Structorizer sind sie es nicht. Sie können Ausdrücke enthalten und verwenden. Elemente von Nassi-Shneiderman-Diagrammen repräsentieren Anweisungen, keine Ausdrücke. Sie können einfach (atomar: Instruction-, Call- oder Jump-Elemente) oder strukturiert (d. h. sie enthalten verschachtelte Elemente, jede andere Art von Element) sein.
- Eine Zuweisung ist eine Anweisung (siehe Instruction im Benutzerhandbuch):
<assignment> ::= <var_desig> ( <- | := ) <expression>
In einigen Programmiersprachen (wie C) sind Zuweisungen selbst Ausdrücke und können daher als Terme in komplexeren Ausdrücken verwendet werden – dies gilt in Structorizer jedoch nicht. - Ein Prozeduraufruf ist eine Anweisung (Instruction). Je nachdem, ob die referenzierte Prozedur eine eingebaute ist oder sich auf ein benutzerdefiniertes Unterroutinen-Diagramm bezieht, ist entweder ein Instruction-Element oder ein Call-Element erforderlich, um den Prozeduraufruf zu platzieren.
<proc_call> ::= <identifier> ( <expression_list> ) - Weitere Anweisungen sind:
- Eingabe-Anweisung:
<input_statement> ::= <input> [ <literal_string> [,] ] [ <var_desig> { , <var_desig> } ] - Ausgabe-Anweisung:
<output_statement> ::= <output> <expression_list>
- Eingabe-Anweisung:
- In einer weiten Interpretation (z. B. C usw.) könnten Typdefinitionen, Konstantendefinitionen und Variablendeklarationen ebenfalls als Anweisungen betrachtet werden. Im engeren Sinne (z. B. Pascal) sind sie es nicht. Structorizer platziert sie in Instruction-Elementen, sodass sie hier unter dem Begriff „Anweisung" subsumiert werden können.
- Konstantendefinition:
<const_definition> ::= const <identifier> ( <- | := ) <const_expression>
Ein<const_expression>ist lediglich ein Ausdruck, dessen Wert nur von Literalen und definierten Konstanten abhängt. - Typdefinition:
<type_definition> ::= type <identifier> = ( <record_spec> | <enum_spec> | <array_spec> | <identifier> )
<record_spec> ::= ( record | struct ) { <comp_decl> { ; <comp_decl } }
<array_spec> ::= array <dim_ranges> of (<array_spec> | <identifier>) | <identifier> <dim_sizes>
<enum_spec> ::= enum { <enum_item> { , <enum_item> } }
<comp_decl> ::= <identifier> { , <identifier> } : ( <array_spec> | <identifier> )
<enum_item> ::= <identifier> [ = <const_expression> ]
<dim_ranges> ::= | [ <dim_range> { , <dim_range> } ]
<dim_range> ::= <literal_int> .. <literal_int> | <const_expression>
<dim_sizes> := [ <const_expression> { , <const_expression> } ] - Variablendeklaration – entweder als bloße Deklaration oder als initialisierte Deklaration. Im letzteren Fall (und nur dann) wird entweder Pascal-/BASIC-ähnlicher oder C-ähnlicher Stil unterstützt. Für eine bloße Deklaration (d. h. ohne anfängliche Wertzuweisung) ist nur der Pascal-/BASIC-Stil verfügbar.
<variable_declaration> ::= <var_decl> | <var_init1> | <var_init_c>
<var_decl> ::= ( var | dim ) <identifier> { , <identifier> } ( : | as ) (<array_spec> | <identifier>)- initialisierte Variablendeklaration:
<var_init1> ::= ( var | dim ) <identifier> ( : | as ) (<array_spec> | <identifier>) ( <- | := ) <expression>
<var_init_c> ::= <identifier> <identifier> [ <dim_sizes> ] ( <- | := ) <expression>
- initialisierte Variablendeklaration:
- Konstantendefinition:
- Return-, Leave-, Exit- und Throw-Anweisungen sind Jump-Anweisungen, die durch eine bestimmte Elementart in Strukturogrammen repräsentiert werden.
<return_stmt> ::= return [ <expression> ]
<leave_stmt> ::= leave [ <literal_int> ]
<exit_stmt> ::= exit <add_expr>
<throw_stmt> ::= throw [ <add_expr> ]
<jump_statement> ::= <return_stmt> | <leave_stmt> | <exit_stmt> | <throw_stmt>
<statement> ::= <assignment> | <proc_call> | <input_statement> | <output_statement> | <jump_statement> | <const_definition> | <type_definition> | <var_declaration> - Jede zusammengesetzte Anweisung (d. h. eine grundlegende algorithmische Struktur wie eine Alternative oder eine Schleife) wird durch eine bestimmte Art von Strukturogrammelement repräsentiert und bedarf daher keiner Syntaxerklärung, mit Ausnahme von FOR-Schleifen.
<for_loop_header> ::= <for> <identifier> ( <- | := ) <add_expr> <to> <add_expr> [ <by> <literal_int> ]
<for_loop_header> ::= <foreach> <identifier> <in> <list_expr>
<list_expr> ::= <qual_name> | <init_expr_a> | <expression_list>