Programm / Unterroutine / Includable
Das leere Diagramm
Wenn Sie Structorizer starten oder ein neues Diagramm anlegen (über die Schaltfläche oder die Taste <Ctrl><N>), erhalten Sie ein leeres Diagramm mit dem Platzhalternamen „???" (das rote Dreieck weist lediglich auf einen zugehörigen Hinweis des Analyser in der unteren Berichtsliste hin):
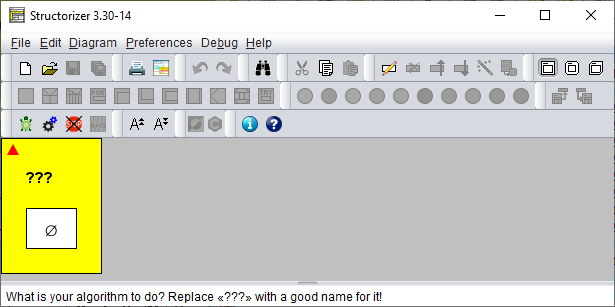
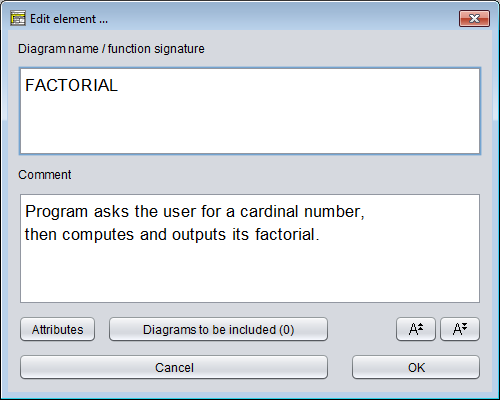
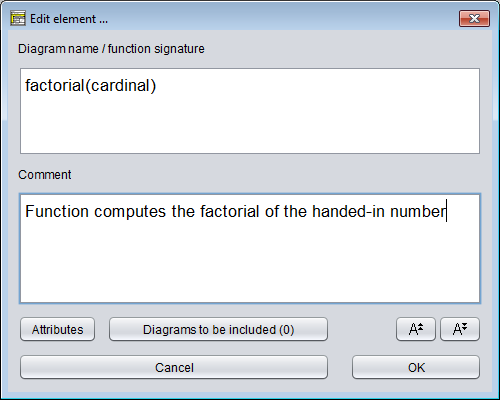
Doppelklicken Sie auf die Fragezeichen und geben Sie im oberen Textfeld „Diagram name / function signature" des dann erscheinenden Element-Editors einen sinnvollen Namen ein.
- Der Name sollte den Zweck des Algorithmus widerspiegeln.
- Der Name sollte ein „Bezeichner" sein, d. h.:
- Der Name sollte keine Leerzeichen enthalten:
THIS IS NOT A GOOD ALGORITHM NAME. - Wenn der Name aus mehreren Wörtern bestehen soll, können Sie die Lücken zwischen den Wörtern mit Unterstrichen füllen:
THE_ALGORITHM_NAME_SHOULD_BE_CONTIGUOUS. - Idealerweise beginnt der Algorithmusname mit einem Buchstaben und enthält nur Buchstaben, Ziffern und Unterstriche (Bezeichner-Syntax).
- Der Name sollte keine Leerzeichen enthalten:
Stellen Sie außerdem sicher, dass Sie das untere Textfeld (beschriftet mit „Comment") mit einer Beschreibung füllen, wozu der Algorithmus gut ist und wie er zu verwenden ist.
Das rahmende (oder Wurzel-)Element eines Nassi-Shneiderman-Diagramms repräsentiert entweder ein Programm, eine (aufrufbare) Unterroutine oder ein Includable-Diagramm (siehe auch die Typ-Einstellung).
- Ein Programm oder Main bezeichnet einen eigenständigen Algorithmus (eine Anwendung), der auf Betriebssystemebene als Prozess ausgeführt werden kann. Es kommuniziert in der Regel mit dem Benutzer über Eingabe- und Ausgabeanweisungen.
- Eine Unterroutine bezeichnet typischerweise einen parametrisierten Algorithmus, der zur Ausführung einer untergeordneten Aufgabe innerhalb eines Programms oder einer anderen Routine verwendet werden kann, z. B. um die Fläche eines Kreises mit gegebenem Radius, das Volumen eines Quaders oder den Durchschnitt (Mittelwert) einer gegebenen Zahlenliste zu berechnen. Oder Sie möchten mit dem Turtleizer-Werkzeug eine bestimmte Figur mehrfach an verschiedenen Stellen zeichnen. Unterroutinen haben in der Regel keinen Zugriff auf Variablen außerhalb ihres Gültigkeitsbereichs, erhalten jedoch die benötigten Werte beim Aufruf über Parameter. Umgekehrt geben sie möglicherweise einen Ergebniswert an die aufrufende Ebene zurück. Während Unterroutinen wie die Berechnung des Sinus eines Winkels oder die Quadratwurzel einer Zahl bereits eingebaut sind (ebenso wie z. B. die Drehung der Schildkröte um einige Grad im Turtleizer), können beim Zerlegen eines algorithmischen Problems komplexere Teilaufgaben entstehen. Dann werden Sie in der Regel feststellen, dass es hilfreich ist, eigene Unterroutinen zu definieren, insbesondere wenn Sie diese mehrfach mit unterschiedlichen Parameterwerten ausführen müssen. Und Sie sollten einen Algorithmus, der zu groß wird, um den Überblick zu behalten, zerlegen (Struktogramme sind nicht dazu gedacht, die Größe eines Fußballfeldes zu erreichen!). Je nachdem, ob Unterroutinen einen Wert zurückgeben oder nicht, werden sie üblicherweise unterteilt in:
- Prozeduren, die keinen Wert zurückgeben (und eher eine Wirkung auf die Umgebung haben);
- Funktionen, die ein Ergebnis zurückgeben sollen (üblicherweise ohne weitere Auswirkungen oder Nebeneffekte).
- Ein Includable-Diagramm (eingeführt mit Version 3.27) ist typischerweise eine Sammlung von Konstantendefinitionen, Typdefinitionen und Variablendeklarationen, die z. B. zwischen einem Hauptdiagramm und einigen seiner Unterroutinen geteilt werden sollen. Um auf die definierten Daten zugreifen zu können, muss ein Diagramm das Includable-Diagramm durch Hinzufügen zur Include-Liste einbinden, die über die Schaltfläche „Diagrams to be included" am unteren Rand des Editors erreichbar ist.
Structorizer ermöglicht es Ihnen, visuell zu unterscheiden, ob ein erstelltes Diagramm als Programm, Unterroutine oder Includable-Diagramm gedacht ist — sie unterscheiden sich in der Form des umgebenden Rahmens:
- Ein Programmdiagramm hat eine rechteckige Form,
- die Ecken eines Unterroutinen-Diagramms sind abgerundet,
- ein Includable-Diagramm hat zwei abgeschrägte Ecken.
Wie stellt man den Diagrammtyp ein?
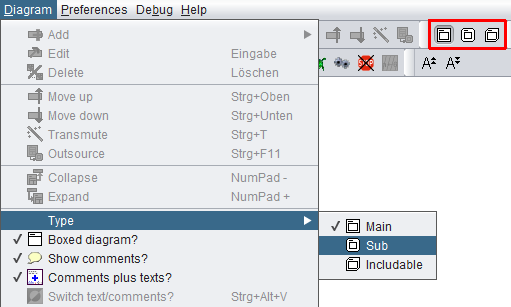
Wählen Sie einfach den entsprechenden Menüpunkt "Diagram › Type › Main" / "Diagram › Type › Sub" / "Diagram › Type › Includable" (siehe Screenshot) oder eine der rot umrahmten Symbolleisten-Schaltflächen im Screenshot (vgl. Settings/Type).
Wenn Sie mit einem neuen Diagramm beginnen, ist es anfangs vom Programmtyp. Die folgenden Abbildungen zeigen die Berechnung der Fakultät sowohl als Programm (links) als auch als Funktion (rechts). Beachten Sie, dass die Zuweisung an die Variable result eine von drei unterstützten Rückgabemechanismen für Werte ist (siehe letzter Absatz unten).

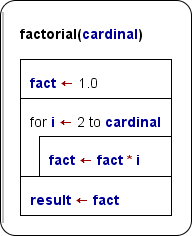
Um Ihnen eine Unterroutinen-Simulation auf der obersten Ebene zu ermöglichen (d. h. ohne aufrufenden Kontext), wird der Executor vor der Ausführung für jeden Funktionsparameter einen Eingabedialog und nach Abschluss einen Ausgabedialog mit dem berechneten Ergebnis anzeigen. (Dies ist jedoch nur der Fall, wenn Sie ein Unterroutinen-Diagramm auf oberster Ebene ausführen.)
Diagrammkopfzeile
Wenn das Diagramm ein Programm (Main) oder ein Includable-Diagramm ist, soll das Textfeld lediglich seinen Namen enthalten. Ein Programmname sollte ein Bezeichner sein, wie oben beschrieben, d. h. ein Wort bestehend aus Buchstaben, Ziffern und Unterstrichen, das mit einem Buchstaben oder Unterstrich beginnt. Es sollte keine Leerzeichen enthalten.
Eine Unterroutinen-Kopfzeile soll jedoch mehr Informationen als nur den Namen enthalten. Auf den Unterroutinennamen (ein Bezeichner wie oben beschrieben) folgt eine Parameterliste. Eine Parameterliste ist in ihrer einfachsten Form ein Klammerpaar, das eine durch Komma oder Semikolon getrennte Folge von Parameternamen enthält (siehe Beispiel oben).
Eine typisierte Unterroutinen-Kopfzeile in Structorizer kann verschiedenen syntaktischen Stilen folgen:
- Sie kann Pascal-Syntax haben (wobei jeder Parametername von einem Doppelpunkt und einem Typnamen gefolgt wird. Die Parameterspezifikationen sind durch Semikolons zu trennen. Wenn mehrere Parameter denselben Typ haben, können sie zu einer durch Komma getrennten Namensliste zusammengefasst werden, gefolgt vom gemeinsamen Doppelpunkt und Typnamen; beachten Sie das Semikolon zwischen Parametergruppen! Der Ergebnistyp — falls vorhanden — folgt der Parameterliste, von ihr durch einen Doppelpunkt getrennt), z. B.:
functionName(var1, var2 : Cardinal ; var3 : Double) : Double - Alternativ kann sie C/Java-Syntax haben (wobei der Name eines Parameters seinem Typnamen folgt; alle Parameterspezifikationen sind durch Kommas getrennt, eine Gruppierung gleichartiger Parameter ist nicht möglich, Semikolons sind nicht erlaubt; der Ergebnistyp steht vor dem Funktionsnamen), z. B.:
double functionName(int var1, int var2, double var3) - Sie kann auch in BASIC-ähnlicher Syntax ausgedrückt werden (sehr ähnlich der Pascal-Syntax, außer dass das Schlüsselwort
asanstelle des Doppelpunkts verwendet wird und weder Parametergruppierung noch Semikolons erlaubt sind), z. B.:
functionName(var1 as Integer, var2 as Integer, var3 as Double) as Double
Alle drei Formen werden von Structorizer akzeptiert und bei einem Code-Export wenn möglich in korrekte Funktionsköpfe umgewandelt. Seit Version 3.32-36 wird das Wort „void" für den Ergebnistyp (wie in C, Java usw. bei Routinen ohne Rückgabewert üblich) von Structorizer als gleichwertig mit einem weggelassenen Ergebnistyp erkannt, d. h., es wird kein Rückgabewert erwartet.
Structorizer erlaubt sogenanntes Überladen von Unterroutinen, d. h. mehrere Unterroutinen dürfen denselben Namen haben, sofern sich ihre Parameteranzahl unterscheidet. Da die Typisierung von Parametern (und Variablen im Allgemeinen) weder obligatorisch noch durchgängig erzwungen ist, wenn Datentypen zufällig angegeben werden, versucht Structorizer nicht, Argumentlisten nach Argumenttypen zu unterscheiden. Nur die Anzahl der Argumente macht einen wesentlichen Unterschied.
Beachten Sie jedoch, dass die Reihenfolge der Parameter wichtig ist: Der erste Argumentwert eines Aufrufs wird stets dem ersten Parametervariablen der passenden Unterroutine zugewiesen und so weiter (Argumentzuweisung nach Position).
Seit Version 3.29-05 unterstützt Structorizer optionale Parameter, wie viele Programmiersprachen (z. B. C++, C#, Python, VisualBasic, Delphi usw.) dies tun. Das bedeutet, dass eine Unterroutine mit einer verkürzten Argumentliste aufgerufen werden kann; der Aufruf kann einige rechtsseitige Argumente weglassen, für die dann Standardwerte verwendet werden. Um diese Möglichkeit zu nutzen, müssen Sie die Standardwerte in der Unterroutinen-Kopfzeile angeben — hängen Sie einfach ein Gleichheitszeichen mit einem konstanten Wert (einem Werteliteral) an die optionalen Parameter an, z. B.:
double func1(int var1, int var2 = 3, double var3 = -8.7)
func2(var1, var2 : Cardinal; var3 : Double = 2.6E9) : DoubleEs ist jedoch wichtig, dass Standardwerte lückenlos von rechts nach links vergeben werden müssen. Mit anderen Worten: Wenn Sie den ersten Parameter optional machen, müssen alle nachfolgenden Parameter ebenfalls optional sein. Ebenso kann ein Aufruf nur eine Anzahl von Argumenten am Ende der Liste weglassen, nicht mittendrin (kein selektives Weglassen). Der Bereich möglicher Argumentanzahlen für den Aufruf wird in den symbolischen Signaturen der Diagramme (wie im Arranger-Index dargestellt) angezeigt — für die beiden Demo-Funktionen oben würde dies so aussehen (die Klammern enthalten die minimale und maximale Argumentanzahl, getrennt durch einen Bindestrich):
func1(1-3)
func2(2-3)Rückgabemechanismen
Um einen Wert aus einem Funktionsdiagramm zurückzugeben, haben Sie die Wahl zwischen drei von Structorizer unterstützten Mechanismen (sowohl bei der Ausführung als auch beim Code-Export):
- Weisen Sie den Wert einer Variablen zu, die genau wie die Unterroutine benannt ist (wie in Pascal; im obigen Beispiel könnten Sie die letzte Zeile ändern zu:
factorial <- fact); - Weisen Sie den Wert einer Variablen namens
RESULT,Resultoderresultzu (wie im obigen Beispiel gezeigt); - Fügen Sie eine
return-Anweisung hinzu (wie in C, Java u. ä.; ändern Sie die letzte Zeile im obigen Beispiel zu:return fact).
Die ersten beiden Möglichkeiten erlauben es, einen vorläufig zugewiesenen Wert durch nachfolgende Anweisungen zu überschreiben, sodass lediglich die zuletzt ausgeführte Zuweisung an die Funktionsname- oder result-Variable das endgültige Ergebnis liefert. Eine return-Anweisung hingegen erzwingt sofort die Beendigung der Unterroutine mit dem angehängten Ergebniswert, an welcher Stelle auch immer sie vorkommt und ausgeführt wird.
Sie sollten nicht mehr als einen der drei oben beschriebenen Ergebnismechanismen innerhalb desselben Diagramms verwenden, da das Ergebnis sonst mehrdeutig ist und möglicherweise nicht Ihren Erwartungen entspricht.
Beachten Sie, dass Mechanismus 1 zu Warnungen des Analyser führt, wenn die Option „Check that the program / sub name is not equal to any other identifier" in den Analyser-Einstellungen aktiviert ist.
Hilfsmittel zur Unterroutinen-Erstellung
Structorizer bietet hilfreiche Werkzeuge, um die Erstellung passender Unterroutinen im Rahmen eines Top-Down-Entwurfsparadigmas zu erleichtern:
- Der Menüpunkt "Edit › Edit Subroutine" (anzuwenden auf ein ausgewähltes CALL-Element; auch über das Kontextmenü oder die Tastenbelegung
<Ctrl><Enter>verfügbar) erstellt ein Unterroutinen-Diagramm mit passender Schnittstelle, sofern es noch nicht vorhanden war, und öffnet es zur Bearbeitung. - Der Menüpunkt "Diagram › Outsource" (anzuwenden auf eine ausgewählte Elementfolge; auch über das Kontextmenü oder die Tastenbelegung
<Ctrl><F11>verfügbar) extrahiert die ausgewählten Elemente aus dem aktuellen Diagramm, wandelt die Folge in eine Unterroutine um, leitet die benötigten Argumente und Rückgabewerte ab und ersetzt die Folge durch ein passendes CALL-Element.
(Weitere Details finden Sie unter CALL-Elemente.)
Includable-Diagramme (eingeführt mit Version 3.27)
Der dritte Diagrammtyp unterscheidet sich von den oben genannten Typen in zwei wesentlichen Punkten:
- Er teilt seine definierten Typen, Konstanten und deklarierten Variablen mit allen einbindenden Diagrammen;
- er wird höchstens einmal ausgeführt — vom ersten ausgeführten Diagramm, das es in seiner Include-Liste hält.
Includable-Diagramme wurden eingeführt, um:
- dem Code-Import und -Export einiger Quellsprachen Rechnung zu tragen, bei denen globale Definitionen, Include-Dateien usw. ein gängiges Merkmal sind;
- zusammengesetzte Typen (auch Record, Struct genannt) einführen zu können, die eine Definition erfordern, die möglicherweise zwischen einem aufrufenden Diagramm und einem aufgerufenen Diagramm geteilt werden muss, wenn die Argumentliste zufällig einen Parameter eines solchen Record-Typs enthält.
Während das Teilen von Typen und Konstanten unbedenklich ist, empfiehlt es sich nicht (obwohl es möglich ist), Variablen auf diese Weise zu teilen. Tatsächlich sollte die Verwendung gemeinsamer (globaler) Variablen beim Algorithmenentwurf vermieden werden, weil:
- sie den Datenfluss verbirgt (wenn der Zugriff an den Parameterlisten vorbei erfolgt),
- sie stets das Risiko unerwünschter Wechselwirkungen birgt,
- sie die allgemeine Wiederverwendbarkeit des Algorithmus erheblich einschränkt.

Idealerweise sollten die einzubindenden Diagramme (die „Includable-Diagramme") nur Konstantendefinitionen und Typdefinitionen und — falls unvermeidbar — Variablendeklarationen, Variableninitialisierungen u. ä. enthalten. Das folgende Beispiel zeigt, dass die in Diagramm „GlobalDefinitions" definierte Konstante ultimateAnswer erkannt und daher im importierenden Diagramm „ImportCallDemo" hervorgehoben wird, als wäre sie vom importierenden Diagramm selbst eingeführt worden.
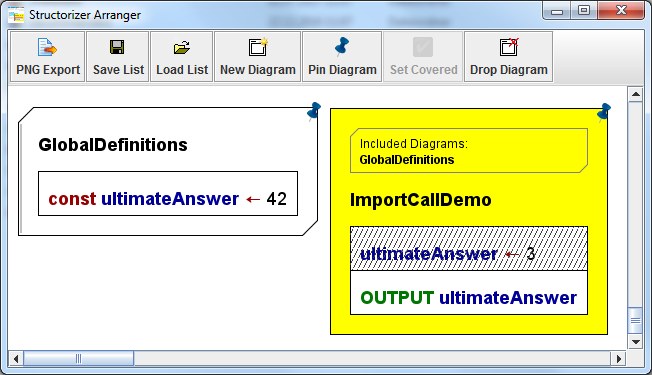
Das rechte Diagramm zeigt die Liste der Namen der einzubindenden Diagramme. Die Liste ist oberhalb des Programmnamens oder der Funktionssignatur positioniert und von einem abgeschrägten Rahmen umgeben, der an die Form eines Includable-Diagramms erinnert.
Die Liste der einzubindenden Diagramme wird über den Element-Editor des einbindenden (abhängigen) Diagramms konfiguriert. Seit Version 3.29 finden Sie am unteren Rand des Element-Editors eine Schaltfläche „Diagrams to be included (#)". Durch Drücken dieser Schaltfläche öffnen Sie den Editor-Bereich für die Include-Liste. Wenn Sie mit der Maus über die Schaltfläche fahren, erscheint ein Tooltip mit allen Include-Namen.
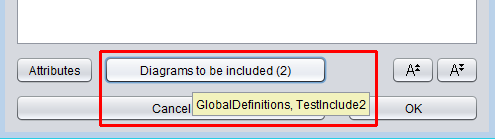
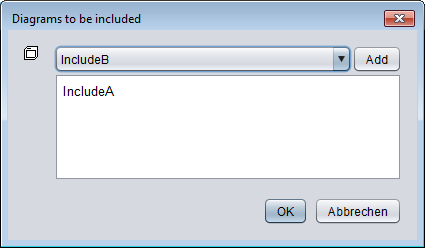
Der Editor-Bereich, der sich beim Drücken der Schaltfläche öffnet, ermöglicht die Konfiguration, welche Includable-Diagramme tatsächlich vom aktuellen Programm / Routine / Includable-Diagramm eingebunden werden sollen. Er enthält einen einfachen Textbereich, in dem Sie die Namen der einzubindenden Diagramme (durch Zeilenumbruch oder Komma getrennt) schreiben oder bearbeiten können. Über dem Textbereich erscheinen eine Auswahlliste und eine einfache „Add"-Schaltfläche, sofern Includable-Diagramme im Arranger zur Auswahl verfügbar sind.
Sie können den Namen eines verfügbaren Includable-Diagramms auswählen und durch Klicken auf „Add" zum Text hinzufügen. Um einen nicht mehr gewünschten Eintrag zu entfernen, löschen Sie ihn einfach aus dem Textbereich. Wenn der hinzuzufügende Eintrag bereits im Textfeld steht, hat die „Add"-Schaltfläche keine Wirkung.
Bei dieser Gelegenheit sei erwähnt, dass eingebundene Diagramme ihrerseits (natürlich) andere Includable-Diagramme einbinden können. Dies kann sogar notwendig sein, um die Ausführungsreihenfolge bei Abhängigkeiten sicherzustellen (wenn Diagramm C die Diagramme A und B einbindet und A vor B ausgeführt werden muss, sollte B seinerseits A einbinden, anstatt sich auf die Reihenfolge in der Include-Liste von C zu verlassen). Es darf jedoch niemals eine zyklische Einbindung entstehen (z. B. Diagramm A bindet Diagramm B ein, das seinerseits Diagramm A einbindet)! Analyser und Executor versuchen ihr Bestes, solche zyklischen Einbindungen zu erkennen und zu verhindern.
Mit Version 3.30-15 erweiterte Structorizer seinen Dienst zur Erleichterung der Bearbeitung oder Erstellung referenzierter Diagramme von aufgerufenen Unterroutinen auf eingebundene Diagramme: Wenn Sie den Rahmen eines Diagramms mit einer nicht leeren Include-Liste auswählen, ändern die Menüpunkte „Edit subroutine ..." im Menü „Edit" und im Kontextmenü ihr Aussehen und ermöglichen es, ein eingebundenes Diagramm in einen Structorizer-Bearbeitungskontext zu laden.
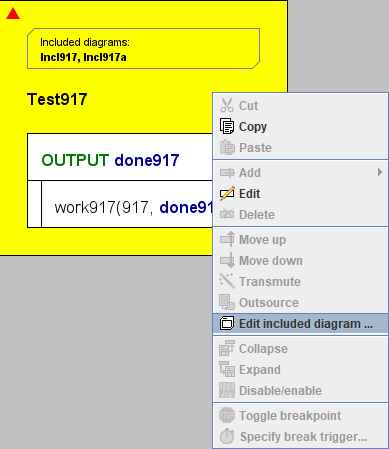
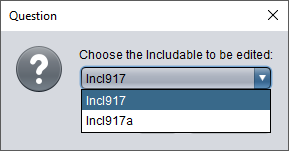
Wenn die Include-Liste des ausgewählten Diagramms mehr als einen Eintrag enthält, werden Sie aufgefordert, unter den aufgelisteten Includable-Diagrammen zu wählen. Wenn der ausgewählte Includable-Name mehrdeutig ist (d. h. mehrere Diagramme mit demselben Namen im Arranger vorhanden sind und die Gruppenzugehörigkeit keine Unterscheidung ermöglicht), werden Sie erneut aufgefordert, unter den vorhandenen Diagrammen zu wählen (diesmal zeigt die Auswahlliste auch die Dateipfade an, da der Name allein keine Unterscheidung erlauben würde). Umgekehrt werden Sie, wenn kein passendes Diagramm im Pool vorhanden ist, gefragt, ob Sie das fehlende Diagramm erstellen möchten.
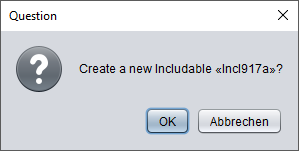
Nach Bestätigung wird ein Includable-Diagramm mit dem gewählten Namen erstellt und im Arranger abgelegt. Falls sich das einbindende („übergeordnete") Diagramm noch nicht im Arranger befand, wird es ebenfalls dorthin verschoben; möglicherweise wird eine neue Anordnungsgruppe um beide Diagramme herum gebildet (sofern das übergeordnete Diagramm noch kein Mitglied einer Gruppe war). Eine zusätzliche Structorizer-Instanz mit dem neuen Diagramm wird geöffnet.
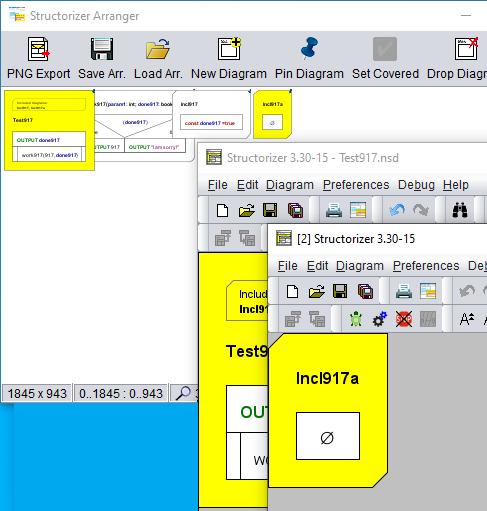
Die neue Structorizer-Instanz erhält den Fokus.
Attribut-Inspektor
Im Element-Editor für Programm/Unterroutine/Includable befindet sich unterhalb des Kommentarfelds eine Schaltfläche „Attributes", die einen „Attribute Inspector"-Dialog öffnet, in dem Sie weitere Metainformationen über das Diagramm einsehen und einige davon festlegen oder ändern können. Für ein neues Diagramm könnte er so aussehen:
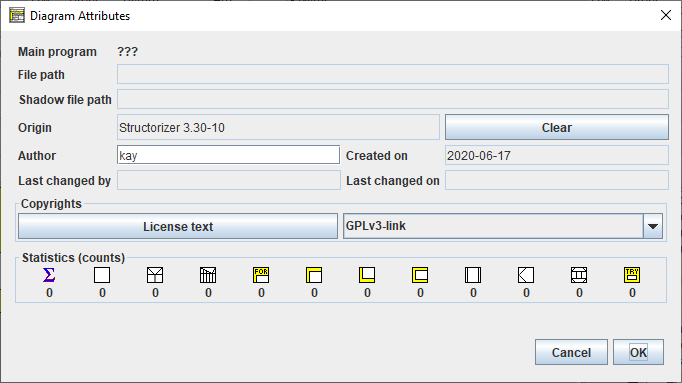
Diesen Dialog können Sie auch über das Dateimenü ("File › Inspect attributes...") oder mit der Tastenkombination <Alt><Enter> aus dem Arbeitsbereich öffnen.
Seit Version 3.28-08 können Sie den „Attribute Inspector" auch für jedes im Arranger befindliche Diagramm über das Kontextmenü des Arranger-Index (sofern ein Diagrammknoten ausgewählt ist) oder den Arranger selbst aktivieren.
Der „Attribute Inspector" ermöglicht es Ihnen, die Metainformationen über das Diagramm einzusehen, einschließlich Pfade, Autor, Erstellungs- und Änderungsdaten, gespeicherte Copyright-Informationen usw. Er zeigt Ihnen auch die Anzahl der enthaltenen Elemente je Typ und kann die abweichenden zugeordneten Schlüsselwörter anzeigen, wenn das Diagramm ohne automatisches Schlüsselwort-Refactoring geladen wurde (aktivierbar in den Import-Einstellungen):
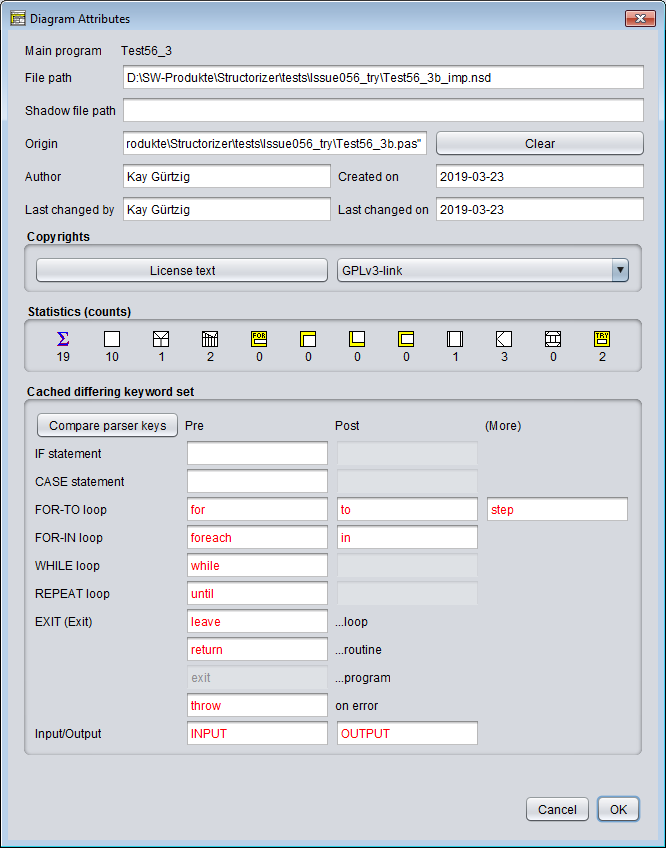
Durch Drücken der Schaltfläche „Compare parser keys" können Sie in einem solchen Fall zusätzlich das Fenster der Parser-Einstellungen im Lesemodus öffnen, um die aktuellen Einstellungen mit denen des Diagramms zu vergleichen (insbesondere die im Attribut-Inspektor rot markierten).