Quelldateien importieren
Quellcode-Import
Structorizer ermöglicht die Ableitung eines Struktogramms aus einer gegebenen Quelldatei (Reverse Engineering). Derzeit steht diese Import-Funktion nur für CLI Pascal, C (ANSI-C99), Java (SE 8), COBOL und Processing-Dateien zur Verfügung; weitere Programmiersprachen werden voraussichtlich folgen.
Beachten Sie, dass die von Structorizer für das Parsing verwendeten Grammatiken in der Regel vereinfacht sind. Es kann daher bei manchen syntaktisch korrekten Code-Beispielen zu Parser-Fehlern kommen, wenn diese zu komplex für ein Reverse Engineering sind oder Besonderheiten enthalten, mit denen Structorizer grundsätzlich nicht umgehen kann. Insbesondere kann Structorizer sogenannten „Spaghetti-Code" nicht sinnvoll importieren. Darunter versteht man Code, der GOTO-Anweisungen oder andere Mittel der Quellsprache nutzt, die mit dem Konzept und den Grundsätzen der strukturierten Programmierung unvereinbar sind. Code mit Zeigern besteht zwar die Syntaxanalyse, aber die resultierenden Diagramme werden nicht ausführbar sein, da der Executor keine Zeigertypen unterstützt. Möglicherweise müssen Sie mit einigen sprachspezifischen Import-Einstellungen (Import Preferences) experimentieren oder solche Quelldateien manuell vorverarbeiten (z. B. Teile herausschneiden oder abändern), um zumindest die wesentliche algorithmische Struktur importieren zu können. Siehe auch den Abschnitt Fehlerbehebung.
Im interaktiven Modus können Sie Quelldateien jeder unterstützten Programmiersprache importieren, indem Sie die entsprechenden Quellen einfach auf Structorizer ziehen (Drag & Drop). Der jeweilige Parser wird automatisch anhand der Dateinamenerweiterung ausgewählt. Ist die Zuordnung mehrdeutig, wird ein Auswahlmenü angezeigt, in dem Sie den geeignetsten Parser auswählen können.
Eine weitere Möglichkeit ist die Verwendung des Menüs: File › Import › Source Code ... (Datei › Importieren › Quellcode ...).
Im dann erscheinenden Dateiauswahl-Dialog können Sie einen geeigneten Dateifilter auswählen (Dropdown-Liste am unteren Rand des Dialogs), um die Suche einzuschränken und die Parser-Auswahl zu präzisieren:
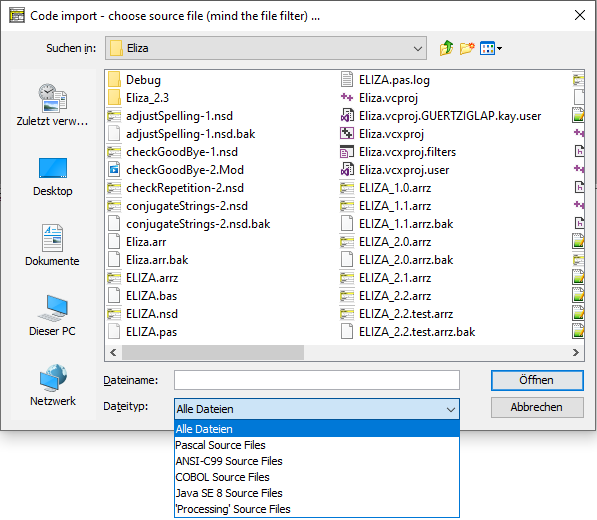
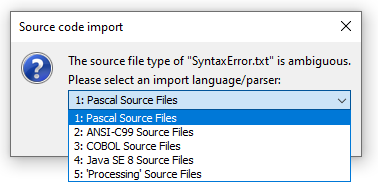
Wenn die Namenserweiterung der ausgewählten Datei zu keinem Dateifilter der verfügbaren Parser passt, öffnet sich ein Auswahl-Dialog, in dem Sie den gewünschten Parser (über den zugehörigen Dateifilter) zuordnen oder den Vorgang abbrechen können:
Der Importer analysiert die Datei gemäß einer bereitgestellten Grammatik und synthetisiert, falls das Parsing erfolgreich war, aus dem abgeleiteten Parse-Baum Kontrollstrukturen. Bestimmte Steuerungsschlüsselwörter (oder Namen von Standardfunktionen) der Quellsprache, die in den Anweisungstexten erkannt werden, können durch die entsprechenden Parser-Einstellungen für dieselben Strukturen ersetzt werden, so wie sie aktuell konfiguriert sind.
Ein Code-Import-Monitor zeigt Ihnen an, in welcher Phase sich der Importprozess befindet, sowie den ungefähren Fortschritt:
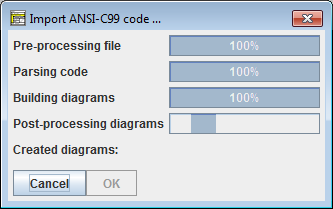
So kann es nach Abschluss eines Imports aussehen:
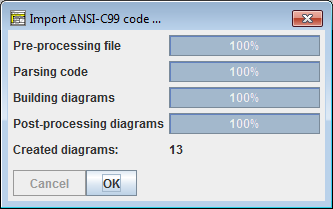
Der Monitor ermöglicht es Ihnen, den Importprozess über die Schaltfläche Cancel (Abbrechen) abzubrechen:
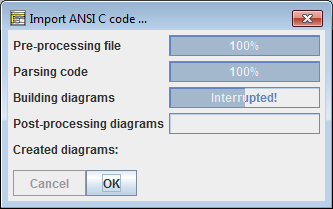
Wenn ein Fehler aufgetreten ist, erhalten Sie ein ähnliches Bild, aber mit dem Hinweis, dass Fehler aufgetreten sind (nach dem Bestätigen wird die Fehlerbeschreibung in einem separaten Fenster angezeigt, siehe weiter unten):
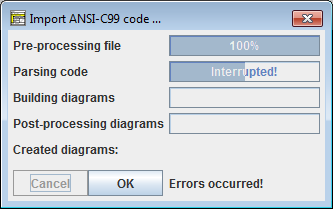
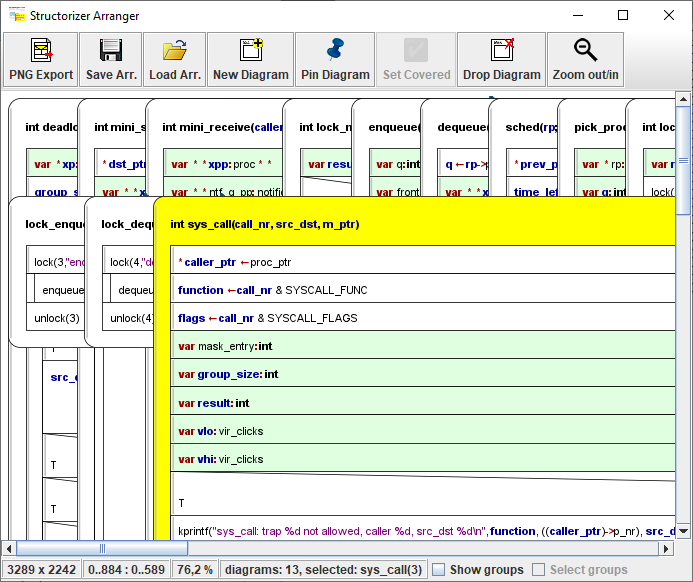
Beim Import einer einzelnen Datei können viele Diagramme entstehen (eines für jede Funktion oder Routine sowie einige Diagramme für gemeinsame Ressourcen). Diese Diagramme werden in den Arranger geladen, sofern ihre Anzahl einen konfigurierbaren Grenzwert nicht überschreitet (siehe Import Preferences (Import-Einstellungen)):
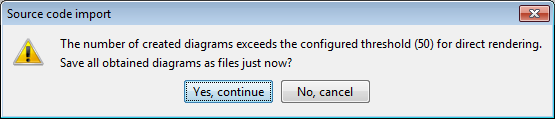
Wird der Grenzwert überschritten, wird angeboten, die Diagramme stattdessen zu speichern, und nur das vermutete Haupt- oder wichtigste Diagramm wird angezeigt:
Wenn Sie das Zielverzeichnis auswählen und den vorgeschlagenen Namen übernehmen oder einen anderen Namen für die erste Datei eingeben, können Sie über eine Zubehör-Checkbox auf der rechten Seite des Dateiauswahl-Dialogs die automatische Übernahme der Namensvorschläge für alle verbleibenden Dateien aktivieren:
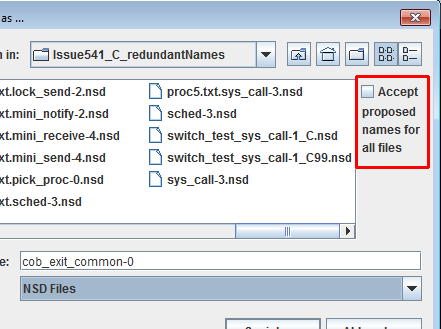
Wenn Sie eine vorhandene Datei überschreiben würden, werden Sie gewarnt und können den Namen ändern, die alte Datei überschreiben, diese Datei überspringen oder das serielle Speichern abbrechen. (Diese Möglichkeit tritt immer auf, wenn Sie den Menüeintrag oder die Schaltfläche „Save All" (Alle speichern) für mehrere Dateien verwenden, die noch nie gespeichert wurden.)
Hinweis: Ab Version 3.30-11 kann ein Modus aktiviert werden, in dem alle interaktiven Code-Import-Möglichkeiten deaktiviert sind (sie erscheinen nicht einmal im Menü). Um diesen Modus zu aktivieren, gehen Sie wie folgt vor:
- Eine structorizer.ini-Datei ist im Installationsverzeichnis als vorrangige ini-Datei abzulegen. Diese Datei muss eine Zeile
noExportImport=1enthalten (manuell einzufügen, z. B. mit einem Texteditor). - Andere Einstellungen in dieser Datei sind nicht erforderlich, es sei denn, sie sollen ebenfalls vorrangig gelten.
Syntaktische Einschränkungen
Pascal-Quellcode-Import
Beachten Sie, dass zu importierende Pascal-Dateien einen program-, unit-, package- oder library-Header haben müssen. Wenn Sie eine einzelne Unterprogramm-Definition (Prozedur oder Funktion) konvertieren möchten, müssen Sie diese zunächst in eines dieser kompilierbaren Konzepte einbetten, z. B. in eine Unit oder zwischen
program dummy;
und
begin end.
Ab Version 3.32-18 können auch einige ObjectPascal-/Delphi-7-Quelltexte importiert werden und erzeugen halbwegs sinnvolle Diagramm-Sets. Da Nassi-Shneiderman-Diagramme nicht für OOP konzipiert wurden, mussten einige Behelfslösungen eingesetzt werden, um Klassen und Methoden sinnvoll darzustellen. Bezüglich der dabei eingegangenen Kompromisse sei auf den Abschnitt Java-Import verwiesen, der ähnlich anwendbar ist. (Der Analyser wird natürlich fast alles in den resultierenden Diagrammen beanstanden.)
C-Quellcode-Import
C-Quelldateien sollten keine übermäßige Verwendung von extern definierten Präprozessor-Symbolen wie __stdcall, __thiscall oder __cdecl machen. Sie können solche Symbole jedoch als „redundante" Defines in den Import Preferences (Import-Einstellungen) deklarieren, sodass sie automatisch vor dem eigentlichen Parsing entfernt werden.
HINWEIS: Release 3.30 hat den veralteten ANSI-C73-Parser entfernt, der sehr ungünstige syntaktische Einschränkungen aufwies, z. B. akzeptierte er das reservierte Wort unsigned allein (ohne nachfolgende Typnamen wie int oder short) nicht als Typname. Quellcode mit Funktionszeigern konnte ebenfalls nicht geparst werden.
COBOL-Quellcode-Import
Der Import von COBOL-Dateien ist eine etwas heikle Aufgabe. Stellen Sie zunächst sicher, dass das Format (Festformat oder nicht) der Datei in den COBOL-spezifischen Import Preferences (Import-Einstellungen) korrekt eingestellt ist. Die Syntax der Sprache ist sehr eigentümlich; manche der ungewöhnlichsten Konstrukte sind möglicherweise nicht im Import implementiert.
Bestimmte Statement-Typen können eine manuelle oder optional automatische Nachbearbeitung erfordern. PERFORM THRU-Anweisungen werden beispielsweise zunächst in mehrzeilige CALL-Elemente umgewandelt (was Analyser-Warnungen verursacht) und müssen daher anschließend in einzelne Aufrufe aufgeteilt und bereinigt werden. Standardmäßig erfolgt dies automatisch nach dem Import, aber die COBOL-spezifischen Import Preferences bieten Ihnen die Wahl zwischen drei Unterstützungsmodi. Wenn Sie die automatische Bereinigung ablehnen, werden speziell eingefügte Kommentare auf sinnvolle Bereinigungsschritte hinweisen (ab Version 3.32-09):

Die erzeugten Diagramme können auch funktionslose (und daher dauerhaft deaktivierte) Markierungselemente enthalten (abgeleitet vom CALL-Elementtyp), die z. B. die Positionen von Absatz- oder Abschnittsbeschriftungen im COBOL-Code (wo Unterroutinen-Code extrahiert worden sein kann) oder COBOL-Anweisungen anzeigen, die die Importfähigkeiten von Structorizer übersteigen (letztere üblicherweise in Signalrot).
Ein weiteres Beispiel für Import-Unzulänglichkeiten: Manche COBOL-Ausdrücke wie X IS ALPHABETIC-LOWER ohne direkte funktionale Entsprechung in Structorizer werden in Ausdrücke mit Funktionssyntax umgewandelt (hier: isString(x) und isAlphabetic_lower(x)), ohne ausführbare Entsprechung, um die Bedeutung zu vermitteln.
Java-Quellcode-Import (ab Release 3.31)
Die meisten Java-Quelldateien können importiert werden, sofern sie der Java-SE-8-Syntax entsprechen und keine Lambda-Ausdrücke verwenden. Es gibt jedoch einige syntaktische Fallstricke:
- Die schließenden spitzen Klammern von verschachtelten Typargumenten führten früher zu Syntaxfehlern, wenn kein Leerzeichen zwischen ihnen stand (sie wurden als Schiebeoperatoren fehlinterpretiert), z. B. in
HashMap<String, Stack<Integer>> doesntWork.
Version 3.32-18 hat eine Importoption „Separate >> of type parameters to > >" eingeführt, die automatisch Leerzeichen zwischen rechten spitzen Klammern einfügt, sofern diese dorthin gehören (tatsächliche Schiebeoperatoren werden dabei ausgespart), und zwar in der Datei-Vorverarbeitungsphase. Die Option ist standardmäßig aktiv. In manchen Fällen kann sie jedoch die Operatoren>>oder>>>beeinträchtigen. Falls dies ein Problem darstellt, deaktivieren Sie die Option und fügen Sie die Leerzeichen manuell ein, bis das Parsing erfolgreich ist. - Leere Typparameterlisten, wie z. B. in
new ArrayList<>(Arrays.asList(values)), werden vor dem Parsing automatisch entfernt. In bestimmten Fällen kann dasselbe für unspezifische Typparameter wie inClass<?>[]passieren. - Annotationen werden nicht an allen Positionen akzeptiert, an denen die Java-Sprachspezifikation sie erlaubt. Da sie in Structorizer irrelevant sind, können Sie diese vor dem Import einfach entfernen oder auskommentieren.
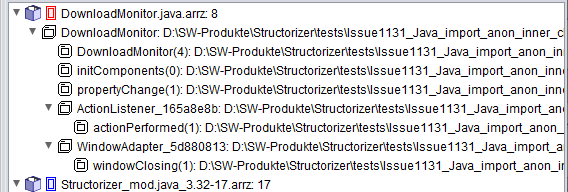
- Anonyme innere Klassen wie im folgenden Code-Ausschnitt werden nur dann in Diagrammelemente umgewandelt, wenn die Java-spezifische Importoption „Dissect anonymous inner classes into diagrams" (Anonyme innere Klassen in Diagramme aufteilen) (eingeführt mit Version 3.32-17) aktiviert ist. Andernfalls würde der Code einfach als Ausdruck (d. h. mehr oder weniger unverändert) in das umgebende Kontextelement (hier ein Instruction-Element) eingefügt:
BaseClass b = new BaseClass(){int doSomethingDifferent(int a){return a * 13;}};
Sie sollten nicht erwarten, dass die aus dem Java-Quellcode-Import resultierenden Diagramme in Structorizer ausführbar sind — Java ist zu tiefgreifend OOP-orientiert, wir können keinen ausreichenden Klassen-Kontext bereitstellen. Es wurden nur begrenzte Anstrengungen unternommen, den Java-Quellstil an die Syntaxeinstellungen in Structorizer anzupassen (in den Import Options (Importoptionen) gibt es eine Java-spezifische Checkbox, mit der der Grad der Syntaxkonversionen konfiguriert werden kann). Eine stärkere Anpassung hätte den Inhalt zu sehr verfremdet, ohne die Chancen auf eine Ausführung oder Fehlersuche wesentlich zu verbessern. Der Hauptnutzen eines Java-Imports liegt in der grafischen Strukturdarstellung, und diesem Zweck wird er gerecht.
Java-Klassen werden durch Includable-Diagramme repräsentiert. Sie werden in die Include-Listen aller Elementdiagramme (Klassen oder Methoden) aufgenommen, damit diese potenziell auf die als Konstanten oder Variablen in den klassen-repräsentierenden Includables deklarierten Felder zugreifen können. Um der hierarchischen Natur von Java-Klassen (mit Element- und lokalen Klassen usw.) Rechnung zu tragen, wurde den Diagrammen ein „Namespace"-Attribut hinzugefügt, das beim Java-Import mit dem Paketpfad (auf oberster Ebene) bzw. dem entsprechenden Klassen-/Methodennamen-Präfix (auf verschachtelten Ebenen) gefüllt wird, sodass der Arranger-Index den Klassenpfad darstellen kann. Wenn nicht leer, zeigt sogar der Editor für Diagramme diesen an (und ermöglicht dessen Bearbeitung):
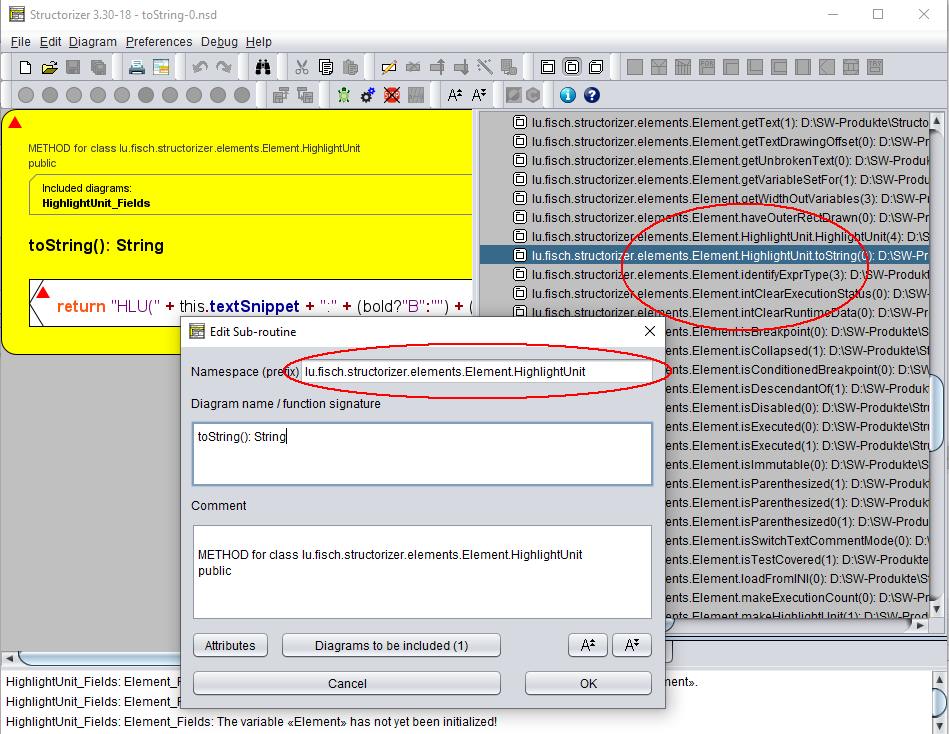
Ein Kontrollkästchen-Menüeintrag „Show qualifiers as prefix" (Qualifizierer als Präfix anzeigen) im Kontextmenü des Arranger-Index ermöglicht es, die Anzeige der „Klassenpfade" zu deaktivieren (siehe Screenshot für den Processing-Import weiter unten). Die hierarchischen Beziehungen zwischen den Diagrammen würden dann stattdessen als mehrstufiger Baum dargestellt (was jedoch mehr Aktualisierungszeit erfordert):
Zusätzlich zu den Unterroutinen-Diagrammen, die Methoden einer Klasse repräsentieren, werden die jeweiligen Methodendiagramm-Header (die Deklarationen) auch als dauerhaft deaktivierte Pseudo-CALL-Elemente eingefügt (wenn die allgemeine Importoption „Import variable (and method) declarations" (Variablen- und Methodendeklarationen importieren) ausgewählt ist). Um die Lesbarkeit zu verbessern, werden die Innentext-Bereiche dieser umgenutzten CALL-Elemente nicht schraffiert (im Gegensatz zur üblichen Deaktivierungsdarstellung, seit Version 3.32-20). Diese Pseudo-CALLs dienen lediglich als eine Art Verknüpfung zu den Methodendiagrammen — über den Menüeintrag „Edit Sub-routine ..." (Unterroutine bearbeiten ...) können Sie das referenzierte Diagramm zur Inspektion in einem zusätzlichen Structorizer-Fenster aufrufen:
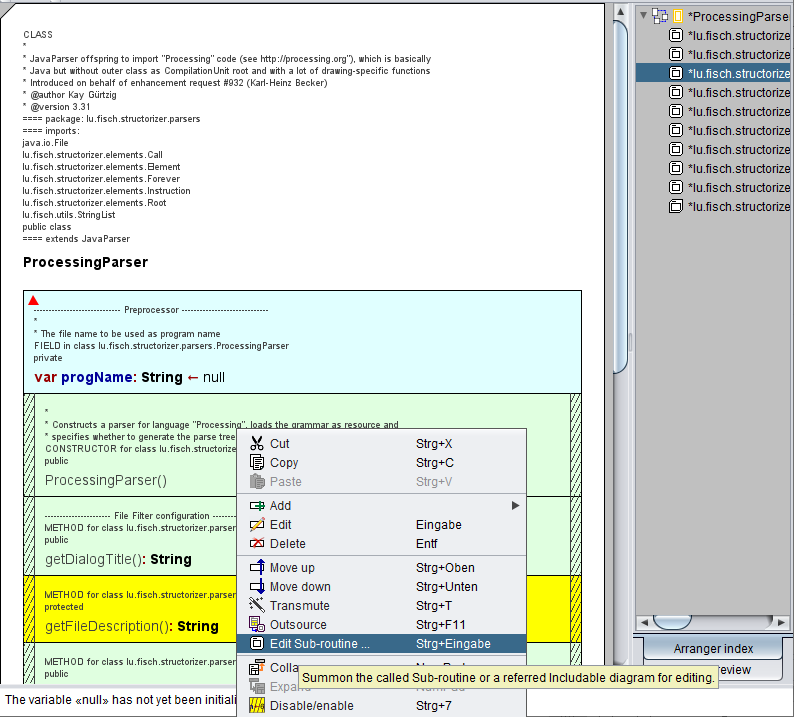
Wie bereits erwähnt, können Sie deren Import deaktivieren (zusammen mit reinen Variablendeklarationen). Sie können die Deklarationen natürlich auch nach dem Import einfach entfernen oder sie über den Anzeigemodus Deklarationen ausblenden verbergen.
Processing-Quellcode-Import (ab Release 3.31)
Processing-Quellcode ist wie Java-Code mit einer impliziten Klasse auf oberster Ebene sowie einem Satz eingebauter Funktionen und Variablen, die als Methoden und Felder dieser impliziten äußeren Klasse betrachtet werden können. Im Gegensatz zu Java ist es keine Allzweck-Sprache, sondern auf 2D- und 3D-Grafikdarstellungen ausgerichtet. Es ist keine main-Methode zum Starten erforderlich. Stattdessen wird eine setup()-Methode implizit als Initialisierung aufgerufen. Danach läuft eine Methode draw() nach der Initialisierung in einer impliziten Endlosschleife. Beim Import in Structorizer spiegelt dies das übliche Processing-Verhalten wider, indem die entsprechenden Aufrufe in das Includable auf oberster Ebene und ein zugehöriges Programm-Diagramm platziert werden (siehe Screenshots unten für ein Beispiel aus der Sprachreferenz).

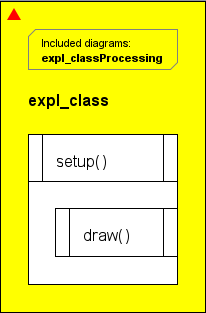
Structorizer spiegelt einige der Standard-„Processing"-Konstanten im Includable-Diagramm wider (siehe oben, deutlich mehr seit Version 3.31-03, jetzt in einem separaten Includable-Diagramm). Wenn der importierte Code einzelne Klassen enthielt, werden diese analog zum Java-Import mit hierarchieabbildenden Qualifizierern im Arranger-Index dargestellt. (Über das Kontextmenü kann die Präfix-Anzeige der Qualifizierer deaktiviert werden und einer tiefen Baumdarstellung weichen):
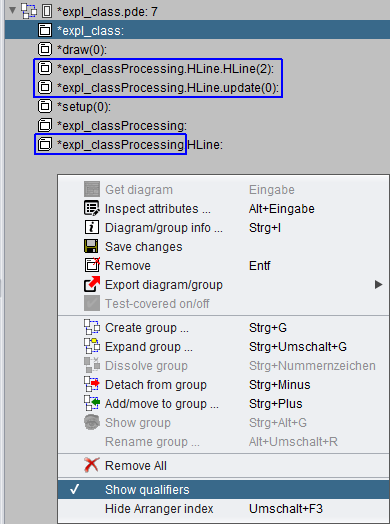
Der Processing-Parser hat noch Schwierigkeiten mit Import-Direktiven am Anfang des Codes. Es empfiehlt sich daher, diese vor dem Parsing einer .pde-Datei auszukommentieren.
Unterroutinen / Methoden
Eine Datei mit mehreren Routinen-Definitionen (oder eine Klasse mit mehreren Methoden) wird in ein Set separater Diagramme umgewandelt, eines für jede Routine, und — wenn nicht leer — ein weiteres für das Hauptprogramm. Wenn Sie den Import innerhalb der Anwendung durchführen (und nicht als Batch-Job, siehe unten), werden die importierten Diagramme im Arranger gesammelt (sofern der konfigurierbare Diagramm-Anzahl-Schwellenwert, eingeführt mit Version 3.28-05, nicht überschritten wird).
Beachten Sie, dass Unterroutinen-Aufrufe (Referenzen auf andere Funktionen) von Structorizer nur dann als solche identifiziert werden können, wenn die entsprechenden Routinen-Definitionen ebenfalls im importierten Code vorhanden sind. Andernfalls werden die entsprechenden Code-Zeilen in der Regel als gewöhnliche Instruction-Elemente eingefügt, können aber manuell in gleichwertige CALL-Elemente umgewandelt werden (zumindest wenn Sie den Algorithmus mit dem Executor ausführen möchten). Diese Element-Umwandlung lässt sich jedoch mit einem einfachen Mausklick durchführen. Die Fähigkeiten zur Identifizierung von Standardroutinen oder Bibliotheksfunktionen, für die es analoge eingebaute Routinen in Structorizer gäbe, sind noch recht begrenzt. (Verbesserungen sind jedoch geplant.)
Definitionen und Deklarationen
Typdefinitionen (insbesondere für Record-/Struct-Typen) und Konstantendefinitionen können für die Interpretierbarkeit von Ausdrücken wesentlich sein. Daher werden sie (ab Release 3.27) importiert. Im resultierenden Diagramm-Set belegen sie Instruction-Elemente, möglicherweise in Includable-Diagrammen, da sie in der Regel global benötigt werden. Konstantendefinitionen werden in Zuweisungsanweisungen umgewandelt (typischerweise rosa eingefärbt und vom jeweiligen Parser mit dem Kommentar „constant!" versehen). Initialisierte Variablendeklarationen werden ebenfalls als Zuweisungen importiert.
Der Import reiner Variablendeklarationen (d. h. ohne anfängliche Wertzuweisung) kann über den Dialog Import Preferences (Import-Einstellungen) aktiviert werden. Importierte (lokale) Deklarationen werden typischerweise in einem blassen Grün eingefärbt. (Ab Version 3.26-02 werden Deklarationen im Pascal- oder VisualBasic-Stil als Inhalt von Instruction-Elementen toleriert.)
Wenn Sie eine Klasse (Java oder Processing) importieren, können Methodendeklarationen dem Includable-Diagramm hinzugefügt werden, das die importierte Klasse repräsentiert. Dabei handelt es sich um dauerhaft deaktivierte Elemente in Form eines CALL, die auf die jeweiligen Methodendiagramme verweisen. Die Erstellung dieser Methoden-Referenz-Elemente hängt von derselben Importoption wie der Variablendeklarationsimport ab.
Kommentare
Der Import von Kommentaren kann ebenfalls über den Dialog Import Preferences (Import-Einstellungen) aktiviert werden. Structorizer versucht nach besten Kräften, im Quellcode gefundene Kommentare dem nächstliegenden Element zuzuordnen, dem sie angehören könnten.
Hinweis: Manche Code-Dateien, die aus Structorizer exportiert wurden, können beim Re-Import Fehler verursachen, wenn sie nicht vorher manuell vervollständigt wurden. (Achten Sie auf TODO- oder FIXME-Kommentare im generierten Code.) Deklarationsabschnitte z. B. in Pascal-Exporten aus früheren Structorizer-Versionen können nur Kommentare enthalten; Pascal-Quelldateien dürfen jedoch keine leeren Deklarationsbereiche enthalten (z. B. ein var-Schlüsselwort ohne danach deklarierte Variablen).
Globale und gemeinsam genutzte Inhalte
Hinweis: Globale Deklarationen und Initialisierungen (z. B. aus C-Quelldateien) werden in sogenannte Includable-Diagramme platziert, die in der „Include-Liste" des Hauptprogramm-Diagramms (sofern eines aus der Datei hervorgegangen ist) und jener Routinen-Diagramme referenziert werden, die auf sie verweisen. Zusätzlich werden globale Deklarationen nach dem Import auf einem hellcyanen Hintergrund dargestellt. Der C-Import unterstützt nur eine minimale Teilmenge des C-Präprozessors (einfache #defines ohne Argumente); von #include und #if in jeglicher Variante sollte keine Funktion erwartet werden. Wenn der Code stark von diesen abhängt, können Sie den C-Quellcode durch den Präprozessor Ihres Compilers laufen lassen (z. B. gcc -E) und den vorverarbeiteten Quellcode importieren, um die Ergebnisse zu vergleichen oder die Parser-Einschränkungen zu umgehen.
Fehlerbehebung
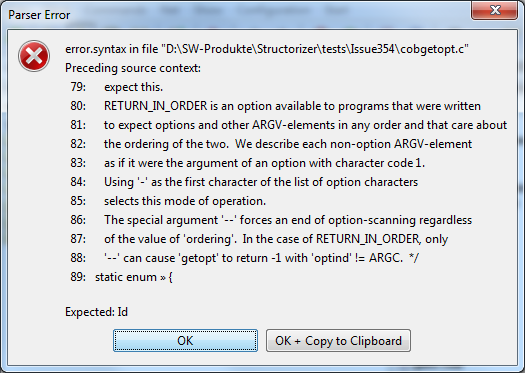
Wenn der zu importierende Code nicht mit der verwendeten Import-Grammatik kompatibel ist, wird Ihnen ein Fehlerdialog wie oben gezeigt angezeigt, in dem immer die letzten 10 Code-Zeilen zur besseren Orientierung angezeigt werden — denn die Zeilennummern stimmen möglicherweise nicht genau mit denen des Originaltexts überein, weil in einer Vorverarbeitungsphase üblicherweise einige problematische Teile des Quellcodes herausgeschnitten werden. In der letzten Zeile zeigt ein kleines Pfeilsymbol (») das Zeichen oder Token an, an dem der Parser ein Problem festgestellt hat. Wie üblich kann das Parsing-Versagen tatsächlich durch vorangehende Teile des Codes verursacht worden sein. Die Meldungsbox informiert Sie auch darüber, welche Art von Symbolen der Parser erwartet hätte. Für eine tiefere Analyse können Sie die Import-Protokolldatei (Log-Datei) einsehen, die im Ordner der importierten Datei abgelegt wird. Ihr Name wird automatisch aus der Quelldatei selbst abgeleitet.
Häufig ist es ein iterativer Prozess, komplexe Quelldateien zu importieren, bei dem Sie möglicherweise schrittweise einige Importoptionen ändern müssen, um bestimmte Probleme zu überwinden (und dabei auf andere zu stoßen). Manchmal kann es sogar erforderlich sein, die Quelldatei zu modifizieren.
Wenn Sie bei offensichtlich korrekten Quelldateien immer wieder Fehler beim Import erhalten, kann die Protokolldatei des Parsers (neben Ihrer Quelldatei, sofern aktiviert) bei der Analyse hilfreich sein. Sie enthält die während der Vorverarbeitung gelesenen Token, möglicherweise einen Token-Bericht aus dem eigentlichen Parsing, und die versuchten Reduktionsregeln während der Build-Phase. Im Fehlerfall ist auch die Fehlermeldung dort enthalten. Möglicherweise sagt Ihnen der Inhalt nicht viel, aber wenn Sie beim Entwickler-Team um Hilfe bitten, wird die Protokolldatei des Parsers sehr geschätzt.
Wenn die Vorverarbeitung erfolgreich ist, das Parsing aber ständig fehlschlägt, und Sie vermuten, dass eine fehlerhafte Vorverarbeitung die Probleme verursacht, kann die vorverarbeitete Zwischenquelldatei sehr hilfreich sein. Sie befindet sich in Ihrem temporären Verzeichnis (Speicherort ist betriebssystemabhängig) und heißt:
Structorizer<kryptische_Hex-Zeichenfolge>.<Erweiterung>
wobei <Erweiterung> die dateinamenerweiterungs-spezifische Endung der Quelldatei ist (z. B. „c", „pas" oder ähnlich). Datum und Uhrzeit der Datei können helfen, die relevante zu identifizieren.
Eine dritte hilfreiche Datei ist die Parse-Baum-Datei, falls das Parsing erfolgreich war, aber der Diagramm-Builder Probleme verursacht.
Schließlich sollten Sie die allgemeine Protokolldatei im Ordner .structorizer Ihres Heimverzeichnisses beachten. Suchen Sie nach den aktuellsten (oder am wenigsten veralteten) Protokolldateien. Sie müssen Structorizer möglicherweise schließen, um eine vollständig geschriebene Datei zu erhalten.
Informationen dazu, wo Sie die entsprechende Protokollierung aktivieren können, finden Sie unter Import Preferences (Import-Einstellungen).
Batch-Import
Structorizer kann auch im Batch-Modus verwendet werden, um eine Quelldatei (Pascal, C oder COBOL) in eine NSD-Datei oder, häufiger, in einen Satz von NSD-Dateien oder ein Anordnungs-Archiv zu konvertieren. Die Befehlssyntax ist nachfolgend angegeben, wobei der unterstrichene Pseudo-Programmname Structorizer durch den jeweiligen Batch- oder Shell-Skript-Namen für die Konsolenumgebung zu ersetzen ist:
structorizer.shfür Linux, UNIX und Ähnliches;Structorizer.batfür Windows.
Die Skripte befinden sich in den herunterladbaren Structorizer-ZIP-Paketen (diese werden für den Batch-Befehl immer benötigt); versuchen Sie es nicht mit Structorizer.exe!
Structorizer (-p|--parse) [parser-name] [-f] [-z] [-e encoding] [-l max-line-length] [-v log-directory] [-s settings-file] [-o output-file] source-file ...
Die Optionen bedeuten:
-p(oder gleichwertig--parse, ab Version ≥ 3.32-23)- Muss die erste Option sein und gibt die Verwendung als Parser an, d. h. für den Quellcode-Import. Wenn Sie keinen expliziten parser-name angeben, schließt Structorizer aus den Dateinamenerweiterungen, welcher Code-Parser zu verwenden ist. Dies gilt dateiweise, d. h. die source-file-Liste kann sogar heterogen sein, also gemischte Pascal-, C- und COBOL-Dateien für welche Parser auch immer verfügbar sind.
Wenn Sie (optional) einen parser-name neben dem Schalter-pangeben, überschreibt dieser die automatische Parser-Erkennung und versucht, alle aufgelisteten Dateien mit diesem Parser zu parsen — unabhängig von deren Dateinamenerweiterungen (ab Version 3.28-05). Die derzeit verfügbaren Parameter-Werte für parser-name sind (wobei „|" Synonyme trennt; ANSI-C73 alias CParser wurde mit Release 3.30 entfernt, Java-Se8 und Processing wurden mit Release 3.31 eingeführt):- Pascal | D7Parser
- ANSI-C99 | C99Parser
- COBOL | COBOLParser
- Java-SE8 | JavaParser
- Processing | ProcessingParser
-e(gefolgt von einem Zeichensatz-Namen)- Dient der Auswahl des Zeichensatzes der Quelldatei (für den Pascal-Import ist dies noch weitgehend irrelevant, da die verwendete Pascal-Grammatik keine Nicht-ASCII-Zeichen verarbeitet, sodass diese in einem Vorverarbeitungsschritt einfach entfernt werden).
-f- Erzwingt das Überschreiben einer vorhandenen Datei mit demselben Namen wie die angegebene Ausgabedatei (siehe
-o); andernfalls wird der Ausgabedateiname durch einen hinzugefügten oder inkrementierten Zähler geändert (z. B.output.nsd→output.0.nsd), um die vorhandene Datei zu erhalten. -l(gefolgt von einer nicht-negativen Zahl)- Gibt an, nach wie vielen Zeichen eine Textzeile umgebrochen werden soll, um zu lange Zeilen zu vermeiden. Der Zeilenumbruch berücksichtigt syntaktische Einheiten wie String-Literale (es handelt sich um eine Art Wortumbruch). Bei Angabe von Null wird der automatische Zeilenumbruch unterdrückt. Wenn diese Option nicht angegeben wird, wird das Zeilenlimit aus den in der structorizer.ini-Datei gespeicherten Import-Einstellungen verwendet.
-o(gefolgt von einem Dateipfad oder -namen)- Gibt den Namen der Ausgabedatei an. Wenn nicht angegeben, wird der Ausgabedateiname aus dem Quelldateinamen abgeleitet, indem die Dateinamenerweiterung durch „.nsd" ersetzt wird. Die Erweiterung „.nsd" wird in jedem Fall sichergestellt. Wenn mehrere Quelldateien angegeben wurden, werden ohne Option
-odie NSD-Dateinamen aus den entsprechenden Quelldateinamen abgeleitet; mit Option-ojedoch wird die für die Abwesenheit von Option-fbeschriebene Namensvariation verwendet (es werden Dateien output-file.nsd, output-file.0.nsd, output-file.1.nsd usw. erstellt). Wenn aus einer Quelldatei mehrere Diagramme entstehen, wird die jeweilige Funktionssignatur an den ursprünglichen Basisdateinamen angehängt, z. B. output-file.sub1-0.nsd, output-file.sub2-4.nsd usw. -s(gefolgt von einem Textdateipfad)- Gibt eine settings-file (Einstellungsdatei) an, die zur Abfrage allgemeiner und parser-spezifischer Optionen für den Import verwendet wird. (Ohne Schalter
-swürden die Anwendungsstandards verwendet.) Die Datei muss relevante Schlüssel=Wert-Paare enthalten, wobei die Schlüssel für parser-spezifische Optionen aus dem Parser-Namen und einem entsprechenden Importoptionsnamen bestehen, die mit einem Punkt verbunden sind, während allgemeine Importoptionsschlüssel mit „imp" beginnen, z. B.:C99Parser.definesToConstants=true COBOLParser.fixedColumnText=37 impComments=true
Ab Version 3.29-12 können Sie Importoptionen in der Structorizer-Benutzeroberfläche konfigurieren und nur diese Importoptionen in einer bestimmten ini-Datei speichern, siehe Einstellungen exportieren und importieren. -v(gefolgt von einem Verzeichnispfad)- Bewirkt, dass für jede importierte Datei source-file eine entsprechende Protokolldatei log-directory/source-file.log im angegebenen Ordner erstellt wird, in die Präprozessor, Parser und Diagramm-Builder ihre Protokolldaten schreiben („ausführlicher Modus"). Diese Protokolldateien können bei der Diagnose von Parser-Problemen helfen.
-z- Gibt an, dass, wenn eine Quelldatei mehr als eine Diagrammdatei erzeugt (typischerweise wenn der Quellcode mehrere Routinen enthält), ein komprimiertes Anordnungs-Archiv (mit der Dateinamenerweiterung
.arrz) anstatt loser Dateien erzeugt wird (ab Version 3.29-09). In diesem Fall erbt nur die Archivdatei den Quelldateinamen (oder den mit Option-oangegebenen Ausgabedateinamen); die Diagrammdateien innerhalb des Archivs erhalten Dateinamen, wie sie von den erstellten Diagrammen vorgeschlagen werden, d. h. aus dem Diagrammnamen oder der Unterroutinen-Signatur abgeleitet.
Wenn Option-znicht angegeben wird, wird für jeden Satz von Diagrammen, der aus einer Quelldatei entsteht (soweit mehr als eines vorhanden ist), mindestens eine Anordnungsliste (mit dem Namen der Quelldatei oder der Ausgabedatei und der Erweiterung.arr) erstellt. Auf diese Weise ist es sehr bequem, die verbundenen Diagramme auf einmal in Structorizer oder Arranger zu laden. - source-file
- (ein oder mehrere Dateipfade/Namen) steht für die zu parsenden und in Nassi-Shneiderman-Diagramme (NSD-Dateien) zu konvertierenden Code-Dateien.
Beispiele
structorizer.sh -p testprogram.pas
Der obige Linux/UNIX-Befehl importiert die Datei „testprogram.pas" aus dem aktuellen Verzeichnis als Pascal-Quellcode und erstellt die resultierende NSD-Datei mit dem Namen „testprogram.nsd" (wenn es ein einzelnes Diagramm ist).
Structorizer.bat -p -e UTF-8 -o quicksort.nsd qsort.pas
Dieser MS-DOS-Befehl importiert die Datei „qsort.pas" (aus dem aktuellen Verzeichnis) als UTF-8-kodierte Pascal-Datei und speichert das resultierende Struktogramm in der Datei „quicksort.nsd".
Structorizer.bat -p -e ISO-8859-1 -v . foo.c bar.cob
Dieser MS-DOS-Befehl parst die Quelldateien „foo.c" (als C-Datei) und „bar.cob" (als COBOL-Datei), wobei für beide der Zeichensatz ISO-8859-1 angenommen wird. Die resultierenden Diagramme werden standardmäßig als „foo.nsd" (plus ggf. „foo.0.nsd", „foo.1.nsd" usw.) und „bar.nsd" (plus ggf. „bar.0.nsd", „bar.1.nsd" usw.) im aktuellen Ordner gespeichert. Zudem werden Protokolldateien „foo.c.log" und „bar.cob.log" im aktuellen Verzeichnis geschrieben (Option „-v .").