Spezielle Syntax für ARM
Über den ARM-Generator-Prototyp
Im Aufbau

Seit Version 3.32-02 stellt Structorizer dank Alessandro Simonetta u. a. einen (etwas vorläufigen) prototypischen Generator für ARM-Assemblercode bereit.
ARM-(Assembler-)Code ist eine mnemonische Darstellung von Maschinencode für ARM-Prozessoren, sodass sich der Abstraktionsgrad grundlegend von dem höherer Programmiersprachen wie Pascal, C, Java usw. unterscheidet.
Es müssen zwei Anwendungsfälle (oder Perspektiven) unterschieden werden:
- ARM-Code-Generierung aus einem beliebigen Nassi-Shneiderman-Diagramm. Dies würde eine vollständige Compiler-Fähigkeit erfordern (möglicherweise sogar die Zerlegung von Gleitkomma-Arithmetik in Sequenzen von Byte- und Word-Operationen). Dies kann in diesem frühen Stadium nicht die Aufgabe von Structorizer sein.
- Umwandlung von Algorithmen, die auf der konzeptuellen Ebene von RISC-Prozessorfähigkeiten formuliert sind, von einem Strukturogramm in ARM-Assemblercode. Aus dieser Perspektive ist es möglicherweise nicht einmal wünschenswert, hier zu viel Compiler-Intelligenz zu implementieren. Selbst wenn man dies konzediert, sind die Konvertierungsfähigkeiten dieses frühen Prototyps noch sehr begrenzt. Andererseits erforderte dies einige Ergänzungen, die im Executor nicht funktionieren oder keinen Sinn ergeben (z. B. Adressabruf für eine Variable oder direkter Speicherzugriff als ob es ein Array wäre). Diese Ergänzungen werden im Folgenden kurz erläutert.
Ab Version 3.32-05 verfolgt Structorizer eine zweistufige Strategie, um beide Absichten zu kombinieren: Einerseits kann über die Analyser-Einstellungen eine sehr restriktive Grammatikprüfung auferlegt werden, die Elementzeilen beanstandet, die über die engen ARM-Prozessorfähigkeiten hinausgehen. Über eine entsprechende Exportoption können Sie den ARM-Generator sogar dazu bringen, solche reichhaltigen Anweisungen abzulehnen. Andererseits wird der ARM-Generator in einem evolutionären Entwicklungsprozess erweitert, um immer komplexere Ausdrücke und Anweisungen zu akzeptieren und zu kompilieren. Um diese erweiterten Fähigkeiten zu nutzen, sollten Sie die eben genannten restriktiven Optionen deaktivieren. Erwarten Sie jedoch nicht zu viel — Sie müssen den generierten Code (in der Code-Vorschau) einfach prüfen, um herauszufinden, ob der ARM-Generator damit umgehen konnte oder nicht.
Einige wichtige Fakten in Kürze:
- Der Satz unterstützter Anweisungen ist sehr begrenzt und die Syntax kann sogar von den Structorizer-Konventionen abweichen (siehe Grundlegende Konzepte).
- Bestimmte Variablennamen werden direkt als Maschinenregister interpretiert, und es gibt einige zusätzliche Schlüsselwörter oder Markierungen für bestimmte maschinenorientierte Aspekte.
- Array-Definitionen weichen etwas von den üblichen Konventionen in Structorizer ab (siehe Arrays).
- Records und Enumeratoren werden in diesem Kontext derzeit überhaupt nicht unterstützt.
- Strings können nur in Variablenzuweisungen (besser: Initialisierungen) verwendet werden, um ein Array von Zeichen im „Speicher" zu erstellen.
- Vom generierten Code für einen beabsichtigten Array-Zugriff über eine Kopie einer Variablen oder eines Registers, die mit der Adresse eines Arrays oder Strings assoziiert war, sollte man nicht erwarten, dass er sinnvoll ist.
Register-Zuordnung
Die Variablennamen R0, R1 usw. bis R15 und gleichwertig(!) r0, r1, …, r15 werden als Register der ARM-Prozessorarchitektur interpretiert. Andere Variablen werden Registern zugeordnet, auf die nicht explizit verwiesen wird. Der Registername R15 (oder r15) bezeichnet den Programmzähler und darf nur innerhalb einer Bedingung (Vergleichsausdruck) verwendet werden, aber nicht explizit gesetzt oder in anderen Arten von Ausdrücken verwendet werden.
Wenn mehr als 15 Variablen in einem Diagramm vorkommen, wird der ARM-Generator die Übersetzung verweigern (in Zukunft ist eine mehr oder weniger intelligente Speicherverwaltung vorgesehen). Wenn sowohl der Groß- als auch der Kleinbuchstaben-Registername desselben Registers (gleiche Nummer) in einem Diagramm vorkommen (z. B. R5 und r5), ist das Verhalten undefiniert.
<identifierR> bezeichnet damit einen Bezeichner wie in Grundlegende Konzepte beschrieben, wobei ARM-Registernamen auf besondere Weise behandelt werden.
<register> bezeichnet einen der Registernamen R0, R1, …, R14 oder r0, r1, …, r14.
Ausdruckskomplexität
Die handhabbare Komplexität von Ausdrücken ist derzeit sehr gering. In der Regel können nur „flache" Ausdrücke mit einer Art von Operator (z. B. Addition oder Multiplikation, nicht beides) verarbeitet werden; komplexe Verschachtelung wird nicht unterstützt, Klammern werden ignoriert.
Neben den üblichen Zuweisungsoperatoren sind die einzigen unterstützten Operatorsymbole (im Folgenden als <operator> bezeichnet):
+, -, *, &, |, and, &&, or, ||
Logische Ausdrücke (zur Verwendung in Alternativen, While- und Repeat-Schleifen) können entweder atomar sein oder eine Reihe von einem oder mehreren Vergleichen, die entweder durch and (äquivalent: &&) oder durch or (äquivalent: ||) kombiniert werden, aber nicht beides. Verlassen Sie sich nicht auf Operatorvorrang; Klammern werden intern eliminiert. Atomare logische Ausdrücke können Variablen oder Register sein (die dann implizit darauf getestet werden, von 0 verschieden zu sein); ein Negationsoperator (not oder !) kann angewendet werden. Hinweis: Bei Vergleichen muss der linke Operand immer ein Register oder eine Variable sein (z. B. ist 4 < R5 nicht erlaubt, wohingegen R5 > 4 erlaubt ist).
Beispiele:
isNicenot R5R4 < 17R0 = 'b' or R1 >= R4 or R6 = 0x2e4
Um die Dinge einfach zu halten, wird hier ein kombiniertes Literal-Konzept <int_literal> eingeführt, das entweder ein dezimales ganzzahliges <literal_int> oder ein hexadezimales Literal <literal_hex> ist (siehe Grundlegende Konzepte):
<int_literal> ::= <literal_int> | <literal_hex>Anweisungen
Grundlegende Zuweisung
Die grundlegenden Zuweisungen erlauben nur boolesche Literale, ganzzahlige Literale, Variablen oder eine einzelne Operation zwischen zwei einfachen Termen.
<identifierR> ( <- | := ) (true | false)
<identifierR> ( <- | := ) ( <identifierR> | <int_literal> ) [ <operator> ( <identifierR> | <int_literal> ) ]Beispiele:
test ← falsecount ← R3R4 ← 0x6 + count
Speicher-Lese- und Schreiboperationen
Dies ist eine alternative Möglichkeit, auf den Inhalt eines deklarierten und initialisierten Arrays zuzugreifen (bis Version 3.32-03 werden andere Variablen nicht im Speicher allokiert, sondern auf Register abgebildet).
<identifierR> ( <- | := ) (memory | memoria) '[' <identifierR> [ + <int_literal> ] ']'
(memory | memoria) '[' <identifierR> [ + <int_literal> ] ']' ( <- | := ) <identifierR>Hinweis: Das <identifierR> innerhalb der Klammern kann ein Variablenname oder ein Registername sein, je nachdem, wie das Array deklariert wurde (siehe Array-Unterstützung unten). Das angegebene <int_literal> muss der tatsächliche Adress-Offset und nicht ein Index sein: Es wird keine automatische Indextransformation durchgeführt.
Beispiele:
R6 ← memoria[height]R2 ← memory[R3 + 0x12]memory[R3] ← R8memoria[count + 4] ← r2
Adresszuweisung
Weist die Adresse einer im Speicher gehaltenen Variablen (d. h. eines Arrays) einem Register zu. Die rechte Seite der Zuweisung ähnelt syntaktisch dem Aufruf einer eingebauten Funktion. Das Argument darf kein Registername sein (wenn das Array mit einem Registernamen deklariert wurde, erfolgt die Adresszuweisung automatisch).
<register> ( <- | := ) (address | indirizzo) '(' <identifier> ')'Beispiele:
R5 ← address(storage)R2 ← indirizzo(count)
Zeichenzuweisung und String-Initialisierung
Weist ein Zeichen- oder String-Literal zu:
<identifierR> ( <- | := ) " <character>{<character>} "
<identifierR> ( <- | := ) ' <character> 'Beispiele:
digit ← '3'R9 ← "These are 4 silly words"
Hinweise:
- Ein String-Literal darf nicht leer sein!
- Eine String-Initialisierung bewirkt die Speicherallokation eines Arrays der enthaltenen Zeichen, von denen jedes durch ein ganzes ARM-Word (4 Bytes) repräsentiert wird, was für UTF-32 ausreicht.
- Eine Zeichenliteral-Zuweisung hingegen wird in eine Anweisung umgewandelt, die den Zeichencode als direkten Operanden in das Zielregister lädt.
- Ein String kann im ARM-Code daher nicht verlängert werden (da die Speicherreservierung genau der Länge des String-Literals folgt). Der Export von Diagrammen, die z. B. String-Verkettung verwenden, wird daher keinen verwendbaren ARM-Code erzeugen.
- Seit Version 3.32-04 erfordern Zeichenzuweisungen einfache Anführungszeichen (
') als Begrenzer des Zeichen-Literals. String-Initialisierungen hingegen erfordern, dass das String-Literal mit doppelten Anführungszeichen (") begrenzt wird. - Am Ende des allozierten Strings wird kein abschließendes
'\0'-Zeichen gesetzt, sofern Sie nicht eine ARM-spezifische Exportoption „Strings mit 0-Terminierung speichern" aktivieren. - Nicht-ASCII- und Steuerzeichen werden im exportierten Code durch ihren hexadezimalen Codepunktwert ausgedrückt.
Array-Unterstützung
Arrays müssen zunächst durch eine Anweisung der folgenden Form initialisiert werden, die eine Deklaration über einen spezifischen Low-Level-Datentyp einschließen kann oder nicht (seit Version 3.32-04 muss die Typbeschreibung ähnlich wie in C# oder Java erfolgen, d. h. dem Elementtypnamen muss ein leeres Klammerpaar folgen):
[(byte | hword | word | quad | octa)'['']]' <identifierR> ( <- | := ) '{' <int_literal> { , <int_literal> } '}'Wenn keiner der Typen byte[], hword[] usw. angegeben wird, wird word[] angenommen, was einen 32-Bit-Wert (4 Byte Breite) bezeichnet. Beachten Sie, dass seit Version 3.32-03 eine ARM-spezifische Exportoption steuert, ob die Speicherausrichtung auf ganze Word-Adressen automatisch durchgeführt wird.
Beispiel: word[] array1 ← {56, 7, 98}
Wenn <identifierR> ein Register bezeichnet, wird das Register automatisch mit der Adresse des Arrays assoziiert, während das Array selbst mit einem nicht direkt zugänglichen generischen Label platziert wird.
Dann sollen Zuweisungen der folgenden Art akzeptiert werden:
Lesen aus einem Array:
<identifierR> ( <- | := ) <identifierR> '[' (<identifierR> | <int_literal>) ']'Beispiel: c ← array1[R5]
Schreiben in ein Array:
<identifierR> '[' (<identifierR> | <int_literal>) [ + (<identifierR> | <int_literal>) ] ']' ( <- | := ) <identifierR>Beispiel: array1[R2 + 7] ← R4
Hinweise:
- Beachten Sie, dass ein Array-Elementzugriff derzeit noch nicht in ARM-Code exportiert werden kann, wenn er in anderen Arten von Anweisungen oder Ausdrücken eingebettet ist. Wenn Sie z. B. den Inhalt eines Array-Elements vergleichen möchten, müssen Sie ihn zunächst einer Variablen oder einem Register zuweisen und dann dieses vergleichen.
- Wertelisten in traversierenden FOR-Schleifen (kollektionsgesteuerte Schleifen, FOR-IN-Schleifen) können entweder explizit sein (Array-Literal oder kommagetrennte Liste über ganzzahlige Literale) oder Variablen/Register, die auf ein deklariertes Array von ganzen Zahlen verweisen, um einen erfolgreichen Export zu ermöglichen.
Ein- und Ausgabeanweisungen
Der Export von Ein- und Ausgabeanweisungen wird nur unterstützt, wenn der GNU-Syntaxmodus in den ARM-spezifischen Exportoptionen gewählt ist. Eingabeanweisungen erfordern, dass alle ihre Parameter einfache Variablen (oder Register) sind, d. h. kein Array-Elementzugriff oder Record-Komponentenzugriff ist syntaktisch unterstützt. Die Ausdrucksliste einer Ausgabeanweisung kann Variablen-/Registernamen und ganzzahlige Literale umfassen. Während die restriktive Grammatikprüfung des ARM-Anweisungsebenen-Ansatzes (siehe Anwendungsfall 2 oben) beanstandet, wenn keine Elemente in der Anweisung vorhanden sind oder die Eingabeanweisung einen Prompt-String-Literal enthält, toleriert der Generator diese; ein Prompt-String in Eingabeanweisungen wird ignoriert.
<input_keyword> <identifierR> { , <identifierR> }
<output_keyword> ( <identifierR> | <int_literal> ) { , ( <identifierR> | <int_literal> ) }Beispiele:
INPUT R3, numberOUTPUT number, -21, R3
ARM-Assembler-Anweisungen
Darüber hinaus werden alle Anweisungszeilen, die mit einem der folgenden ARM-Assembler-Mnemoniken beginnen (ohne Berücksichtigung von Groß-/Kleinschreibung), als fertige ARM-Anweisungen betrachtet (ohne weitere Syntaxanalyse; nur Variablennamen werden durch Registernamen ersetzt und nicht mit einem Präfix versehene ganzzahlige Literale erhalten das Präfix #):
add, adc, adcs, and, asr, b, bic, bkpt, cdc, cdp, clz, cmn, cmp, cpsid, cpsie, cpy, eor, ldc, ldm, ldr, lsl, lsr, mcr, mla, mov, mrc, mrrc, mrs, msr, mul, orr, pkhbt, pkhtb, rev, rfe, ror, rrx, rsb, rsc, sel, setend, sbc, smla, smlsd, smmla, smmls, smuadx, srs, ssat, stc, stm, str, sub, swi, sxtab, sxtah, sxtb, sxth, teq, tst, usat, uxtab, uxtah, uxtb, uxth
Konsequenzen der ARM-Syntaxbeschränkungen
Der folgende Screenshot zeigt die Konsequenzen der Syntaxbeschränkungen. Die restriktive Syntaxprüfung beanstandet die Eingabeanweisung mit Prompt-String, während die Code-Vorschau demonstriert, dass der ARM-Generator tatsächlich damit umgehen kann. Er erzeugt sogar effizienteren Code als aus Sequenzen einzelner Ein-/Ausgabeelemente, da wiederholte Zuweisungen an das Adressregister entfallen können:
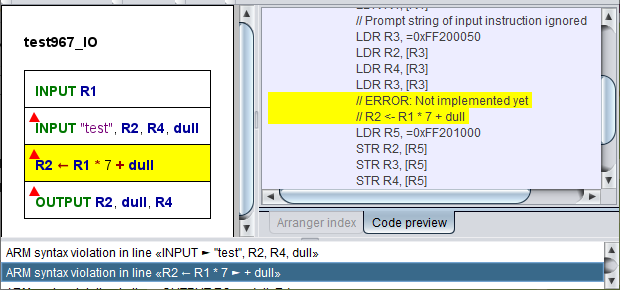
Der oben beanstandete Zuweisungsausdruck mit zwei Operatoren kann tatsächlich noch nicht konvertiert werden.